
صرح جنسن هوانغ، الرئيس التنفيذي لشركة Nvidia، الأسبوع الماضي في بودكاست ليكس فريدمان قائلاً بوضوح: "أعتقد أننا حققنا الذكاء الاصطناعي العام (AGI)." بعد يومين، أطلق الاختبار الأكثر صرامة في أبحاث الذكاء الاصطناعي أحدث معيار له للذكاء الاصطناعي العام—وسجل كل نموذج من النماذج الرائدة أقل من 1%.
أطلقت مؤسسة جائزة ARC هذا الأسبوع ARC-AGI-3، وكانت النتائج قاسية. تصدر نموذج Gemini 3.1 Pro من جوجل القائمة بنسبة 0.37%. وجاء GPT-5.4 من OpenAI بنسبة 0.26%. وحقق Claude Opus 4.6 من Anthropic نسبة 0.25%، بينما سجل Grok-4.20 من xAI صفراً تماماً. في المقابل، حل البشر 100% من البيئات.
هذا ليس اختبار معلومات عامة أو اختبار برمجة، ولا حتى أسئلة صعبة جداً على مستوى الدكتوراه. ARC-AGI-3 هو شيء مختلف تماماً عن أي شيء واجهته صناعة الذكاء الاصطناعي من قبل.
تم بناء هذا المعيار من قبل مؤسسة فرانسوا شوليه ومايك نوب، التي أنشأت استوديو ألعاب داخلياً وخلقت 135 بيئة تفاعلية أصلية من الصفر. الفكرة هي إسقاط وكيل ذكاء اصطناعي في عالم يشبه اللعبة وغير مألوف، بدون تعليمات، وبدون أهداف محددة، وبدون وصف للقواعد. يجب على الوكيل الاستكشاف، وفهم ما هو مطلوب منه، ووضع خطة، وتنفيذها.
إذا كان هذا يبدو وكأنه شيء يمكن لأي طفل في الخامسة من عمره القيام به، فأنت بدأت تفهم المشكلة. إذا كنت تريد أن ترى ما إذا كنت أفضل من الذكاء الاصطناعي، يمكنك لعب نفس الألعاب المعروضة في الاختبار بالنقر على هذا الرابط. لقد جربنا واحدة؛ كانت غريبة في البداية، ولكن بعد بضع ثوانٍ، يمكنك بسهولة إتقانها.
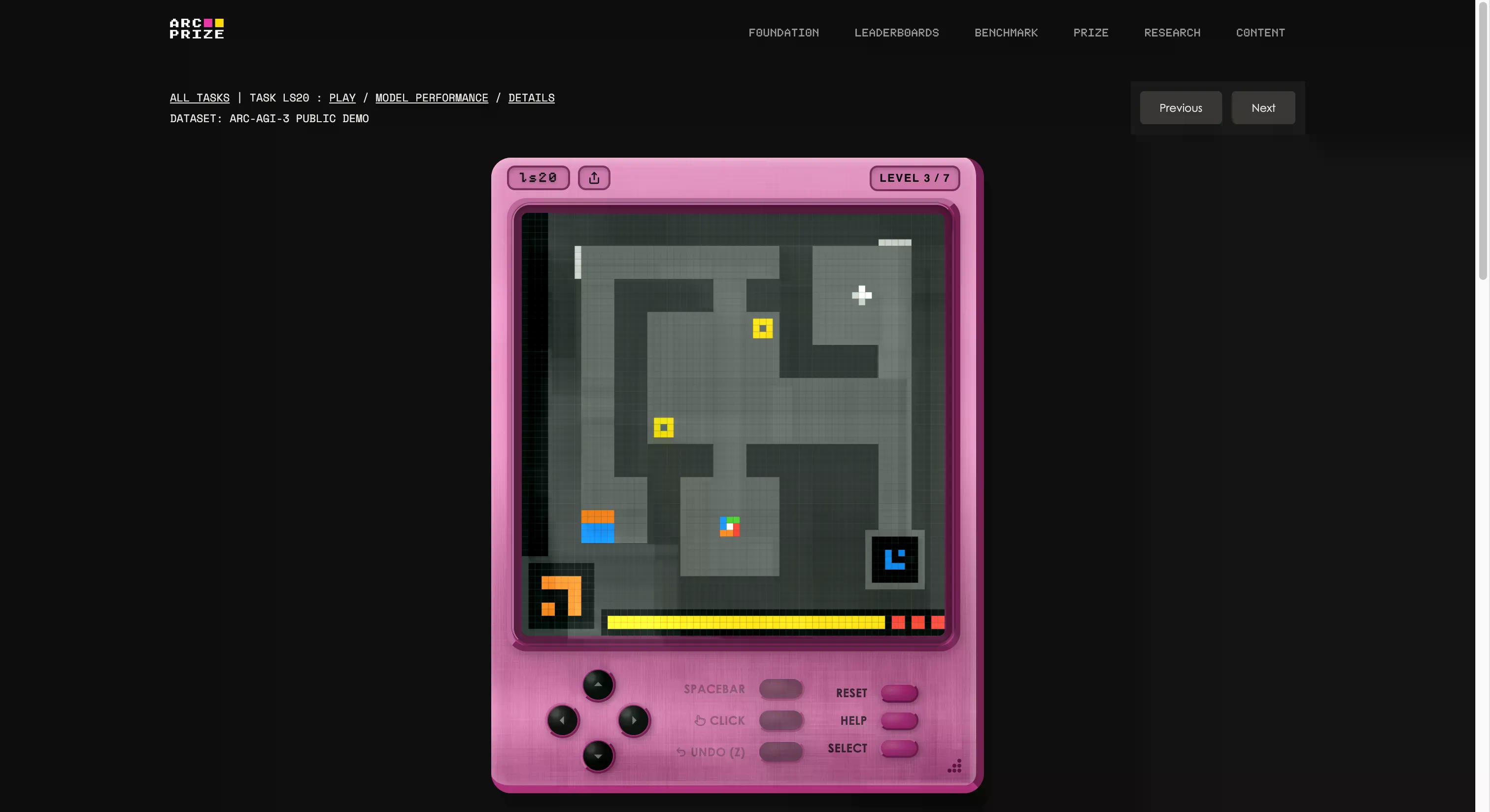
وهو أيضاً أوضح مثال لما تعنيه "G" في AGI (الذكاء الاصطناعي العام). عندما تقوم بالتعميم، تكون قادراً على إنشاء معرفة جديدة (كيف تعمل لعبة غريبة) دون أن يتم تدريبك عليها مسبقاً.
اختبرت الإصدارات السابقة من ARC الألغاز البصرية الثابتة—اعرض نمطاً، وتوقع النمط التالي. كانت صعبة في البداية. ثم قامت المختبرات بضخ قوة الحوسبة والتدريب عليها حتى أصبحت المعايير عديمة الفائدة. وقد فشلت ARC-AGI-1، التي قُدمت عام 2019، أمام نماذج التدريب والتفكير أثناء الاختبار. استمرت ARC-AGI-2 حوالي عام قبل أن يحقق Gemini 3.1 Pro نسبة 77.1%. المختبرات جيدة جداً في استيعاب المعايير التي يمكنها التدريب عليها.
تم تصميم الإصدار 3 خصيصاً لمنع ذلك. مع إبقاء 110 من أصل 135 بيئة خاصة—55 شبه خاصة لاختبار واجهة برمجة التطبيقات (API)، و55 مقفلة بالكامل للمنافسة—لا توجد مجموعة بيانات لحفظها. لا يمكنك شق طريقك بالقوة الغاشمة عبر منطق لعبة جديد لم تره من قبل.
التسجيل ليس نجاحاً/رسوباً أيضاً. تستخدم ARC-AGI-3 ما تسميه المؤسسة RHAE—كفاءة العمل البشري النسبية. الأساس هو ثاني أفضل أداء بشري في المحاولة الأولى. الذكاء الاصطناعي الذي يقوم بعشرة أضعاف الإجراءات التي يقوم بها الإنسان يسجل 1% لذلك المستوى، وليس 10%. تقوم الصيغة بتربيع العقوبة على عدم الكفاءة. التجول والعودة والتخمين للوصول إلى إجابة يتم معاقبته بشدة.
سجل أفضل وكيل ذكاء اصطناعي في المعاينة الخاصة بالمطورين التي استمرت شهراً 12.58%. بينما لم تستطع نماذج LLM الرائدة التي تم اختبارها عبر واجهة برمجة التطبيقات الرسمية، بدون أدوات مخصصة، تجاوز 1%. وقد حل البشر العاديون جميع البيئات الـ 135 بدون تدريب مسبق أو تعليمات. إذا كان هذا هو المعيار، فإن المجموعة الحالية من النماذج لا تفي به.
هناك جدل منهجي حقيقي هنا. يشير تقرير ARC إلى أن نظاماً مخصصاً بنته جامعة ديوك دفع Claude Opus 4.6 من 0.25% إلى 97.1% في متغير بيئي واحد يسمى TR87. هذا لا يعني أن Claude سجل 97.1% في ARC-AGI-3 بشكل عام؛ فقد بقيت نتيجته الرسمية 0.25%، لكن هذا التغيير لا يزال جديراً بالملاحظة.
يغذي المعيار الرسمي الوكلاء برمز JSON، وليس مرئيات. هذا إما عيب منهجي أو دليل على أن النماذج الحالية أفضل في معالجة المعلومات الصديقة للإنسان من البيانات المنظمة الخام. وقد أقرت مؤسسة شوليه بالجدل، لكنها لا تغير التنسيق.
يذكر البحث أن "إدراك محتوى الإطار وتنسيق واجهة برمجة التطبيقات ليسا عاملين مقيدين لأداء النماذج الرائدة على ARC-AGI-3". بعبارة أخرى، يبدو أنهم يرفضون فكرة أن النماذج تفشل لأنها "لا تستطيع رؤية" المهام بشكل صحيح، مجادلين بدلاً من ذلك بأن الإدراك كافٍ بالفعل—وأن الفجوة الحقيقية تكمن في التفكير والتعميم.
وصل فحص واقع الذكاء الاصطناعي العام خلال أسبوع كانت فيه آلة الضجيج تعمل بكامل طاقتها. فبالإضافة إلى تعليق هوانغ، أطلقت Arm على شريحة مركز البيانات الجديدة اسم "معالج AGI المركزي". وقال سام ألتمان من OpenAI إنهم "بشكل أساسي بنوا الذكاء الاصطناعي العام"، وتسوق مايكروسوفت بالفعل مختبراً يركز على بناء ASI: تطور لما يأتي بعد تحقيق الذكاء الاصطناعي العام. يبدو أن المصطلح يتم تمديده حتى يعني كل ما هو مناسب تجارياً.
موقف شوليه أبسط. إذا كان بإمكان إنسان عادي القيام بذلك بدون تعليمات، ونظامك لا يستطيع، فأنت لا تملك ذكاءً اصطناعياً عاماً—بل لديك ميزة إكمال تلقائي باهظة الثمن تحتاج إلى الكثير من المساعدة.
تقدم جائزة ARC لعام 2026 مليوني دولار عبر ثلاثة مسارات تنافسية، تستضاف جميعها على Kaggle. يجب أن تكون جميع الحلول الفائزة مفتوحة المصدر. الوقت يمر، وفي الوقت الحالي، الآلات ليست قريبة حتى.