
Jensen Huang, CEO de Nvidia, estuvo la semana pasada en el podcast de Lex Fridman y dijo, claramente, "Creo que hemos logrado la IAG". Dos días después, la prueba más rigurosa en investigación de IA lanzó su nuevo benchmark de inteligencia artificial general, y todos los modelos frontera puntuaron por debajo del 1%.
La Fundación ARC Prize lanzó ARC-AGI-3 esta semana, y los resultados son brutales. Gemini 3.1 Pro de Google lideró con un 0,37%. GPT-5.4 de OpenAI obtuvo un 0,26%. Claude Opus 4.6 de Anthropic logró un 0,25%, mientras que Grok-4.20 de xAI puntuó exactamente cero. Los humanos, por su parte, resolvieron el 100% de los entornos.
Esto no es un test de trivia, un examen de codificación, ni siquiera preguntas de nivel de doctorado ultra-difíciles. ARC-AGI-3 es algo completamente diferente a todo lo que la industria de la IA ha enfrentado antes.
El benchmark fue creado por la fundación de François Chollet y Mike Knoop, que estableció un estudio de juegos interno y creó 135 entornos interactivos originales desde cero. La idea es introducir un agente de IA en un mundo desconocido tipo juego sin instrucciones, sin objetivos establecidos y sin descripción de las reglas. El agente debe explorar, averiguar qué se supone que debe hacer, formar un plan y ejecutarlo.
Si eso suena como algo que cualquier niño de cinco años puede hacer, estás empezando a entender el problema. Si quieres ver si eres mejor que la IA, puedes jugar a los mismos juegos que aparecen en la prueba haciendo clic en este enlace. Probamos uno; al principio era extraño, pero después de unos segundos, se le coge el truco fácilmente.
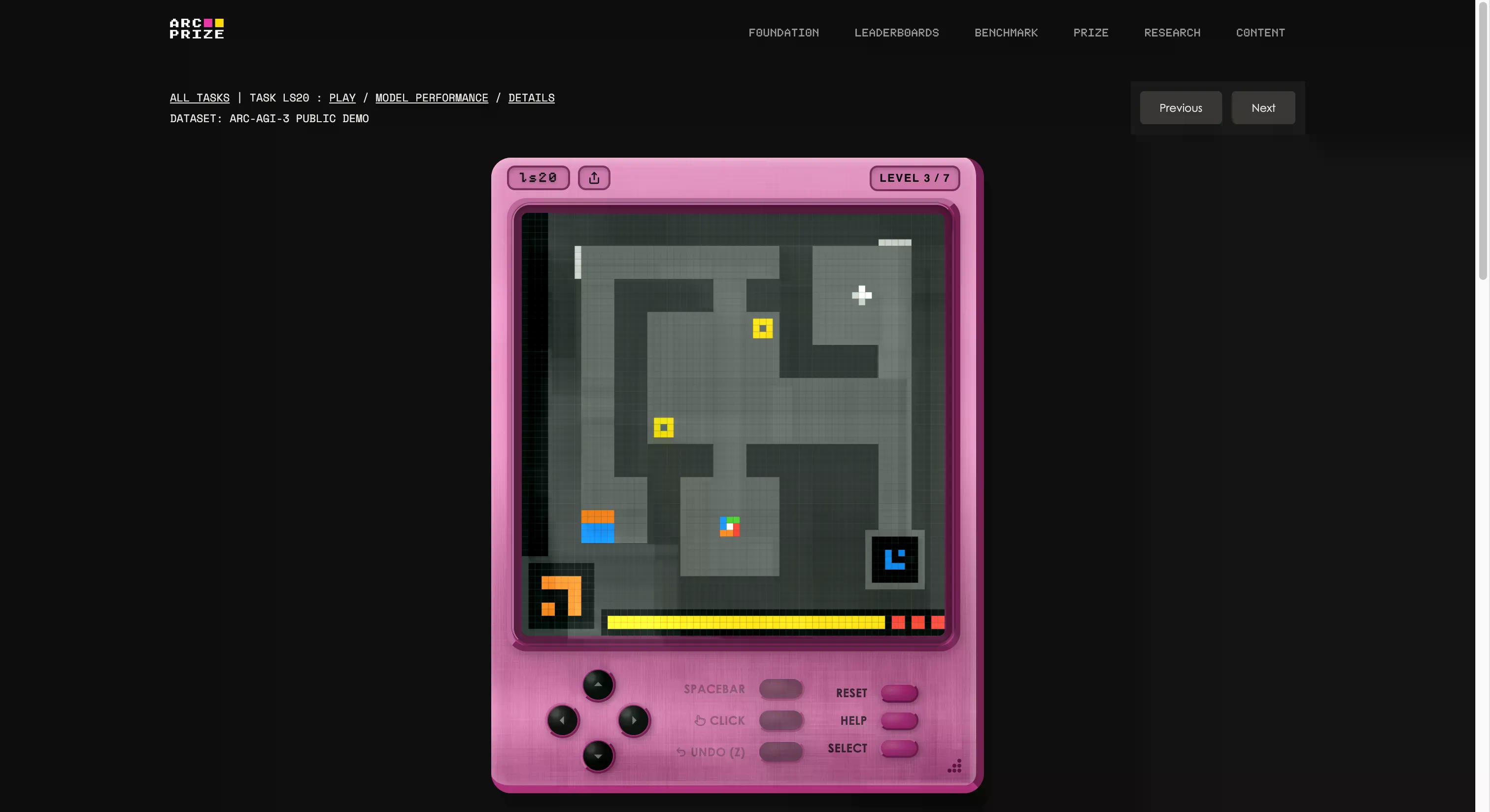
También es el ejemplo más claro de lo que significa la "G" en IAG. Cuando generalizas, eres capaz de crear nuevos conocimientos (cómo funciona un juego extraño) sin haber sido entrenado en ello de antemano.
Las versiones anteriores de ARC probaron rompecabezas visuales estáticos: mostrar un patrón, predecir el siguiente. Al principio eran difíciles. Luego, los laboratorios les dedicaron potencia de cómputo y entrenamiento hasta que los benchmarks quedaron prácticamente obsoletos. ARC-AGI-1, introducido en 2019, sucumbió al entrenamiento en tiempo de prueba y a los modelos de razonamiento. ARC-AGI-2 duró aproximadamente un año antes de que Gemini 3.1 Pro alcanzara el 77,1%. Los laboratorios son muy buenos saturando los benchmarks contra los que pueden entrenar.
La Versión 3 fue diseñada específicamente para evitar eso. Con 110 de los 135 entornos mantenidos en privado —55 semiprivados para pruebas de API, 55 completamente bloqueados para la competición— no hay un conjunto de datos que memorizar. No se puede forzar el paso a través de una lógica de juego novedosa que nunca se ha visto.
La puntuación tampoco es de aprobado/reprobado. ARC-AGI-3 utiliza lo que la fundación llama RHAE—Eficiencia Relativa de la Acción Humana. La línea base es el segundo mejor rendimiento humano en la primera ejecución. Una IA que realiza diez veces más acciones que un humano puntúa un 1% para ese nivel, no un 10%. La fórmula eleva al cuadrado la penalización por ineficiencia. Vagar, retroceder y adivinar la respuesta se castiga duramente.
El mejor agente de IA en la vista previa para desarrolladores de un mes obtuvo un 12,58%. Los LLM frontera probados a través de la API oficial, sin herramientas personalizadas, no pudieron superar el 1%. Los humanos comunes resolvieron los 135 entornos sin entrenamiento previo y sin instrucciones. Si esa es la vara, entonces la actual generación de modelos no la está superando.
Aquí hay un debate metodológico real. El informe de ARC dice que un arnés personalizado construido por Duke impulsó a Claude Opus 4.6 del 0,25% al 97,1% en una única variante de entorno llamada TR87. Eso no significa que Claude obtuviera un 97,1% en ARC-AGI-3 en general; su puntuación oficial en el benchmark se mantuvo en 0,25%, pero el cambio sigue siendo digno de mención.
El benchmark oficial alimenta a los agentes con código JSON, no con elementos visuales. Eso es un defecto metodológico o una demostración de que los modelos actuales son mejores procesando información amigable para los humanos que datos estructurados brutos. La fundación de Chollet ha reconocido el debate, pero no va a cambiar el formato.
“La percepción del contenido del marco y el formato de la API no son factores limitantes para el rendimiento del modelo frontera en ARC-AGI-3”, dice el documento. En otras palabras, parecen rechazar la idea de que los modelos fallan porque “no pueden ver” las tareas correctamente, argumentando en cambio que la percepción ya es suficiente, y la verdadera brecha reside en el razonamiento y la generalización.
La comprobación de la realidad de la IAG llegó durante una semana en la que la máquina de marketing estaba a toda velocidad. Además del comentario de Huang, Arm nombró a su nuevo chip para centros de datos "AGI CPU". Sam Altman de OpenAI ha dicho que "básicamente han construido la IAG", y Microsoft ya está comercializando un laboratorio centrado en construir la ASI: una evolución de lo que viene después de que se logre la IAG. El término se está estirando hasta que significa lo que sea comercialmente conveniente, al parecer.
La postura de Chollet es más simple. Si un humano normal sin instrucciones puede hacerlo, y tu sistema no, entonces no tienes IAG, tienes un autocompletado muy caro que necesita mucha ayuda.
El ARC Prize 2026 ofrece 2 millones de dólares repartidos en tres categorías de competición, todas alojadas en Kaggle. Cada solución ganadora debe ser de código abierto. El tiempo corre, y ahora mismo, las máquinas ni siquiera se acercan.