
Prezes Nvidii, Jensen Huang, wystąpił w zeszłym tygodniu w podcaście Lexa Fridmana i powiedział wprost: „Myślę, że osiągnęliśmy AGI”. Dwa dni później, najbardziej rygorystyczny test w badaniach AI przedstawił swój najnowszy benchmark sztucznej inteligencji ogólnej – a każdy model graniczny uzyskał wynik poniżej 1%.
Fundacja ARC Prize opublikowała w tym tygodniu ARC-AGI-3, a wyniki są brutalne. Gemini 3.1 Pro firmy Google prowadził stawkę z wynikiem 0,37%. GPT-5.4 OpenAI uzyskał 0,26%. Claude Opus 4.6 firmy Anthropic osiągnął 0,25%, natomiast Grok-4.20 firmy xAI zdobył dokładnie zero punktów. Ludzie tymczasem rozwiązali 100% środowisk.
To nie jest test wiedzy ogólnej, egzamin z kodowania, ani nawet ultra-trudne pytania na poziomie doktoranckim. ARC-AGI-3 to coś zupełnie innego niż wszystko, z czym branża AI miała do czynienia wcześniej.
Benchmark został stworzony przez fundację François Cholleta i Mike'a Knoopa, która założyła wewnętrzne studio gier i stworzyła od podstaw 135 oryginalnych interaktywnych środowisk. Ideą jest umieszczenie agenta AI w nieznanym, przypominającym grę świecie, bez żadnych instrukcji, bez określonych celów i bez opisu zasad. Agent musi eksplorować, dowiedzieć się, co ma robić, stworzyć plan i go wykonać.
Jeśli brzmi to jak coś, co potrafi każdy pięciolatek, zaczynasz rozumieć problem. Jeśli chcesz sprawdzić, czy jesteś lepszy od AI, możesz zagrać w te same gry, które są używane w teście, klikając ten link. Wypróbowaliśmy jedną; na początku było to dziwne, ale po kilku sekundach łatwo można było to opanować.
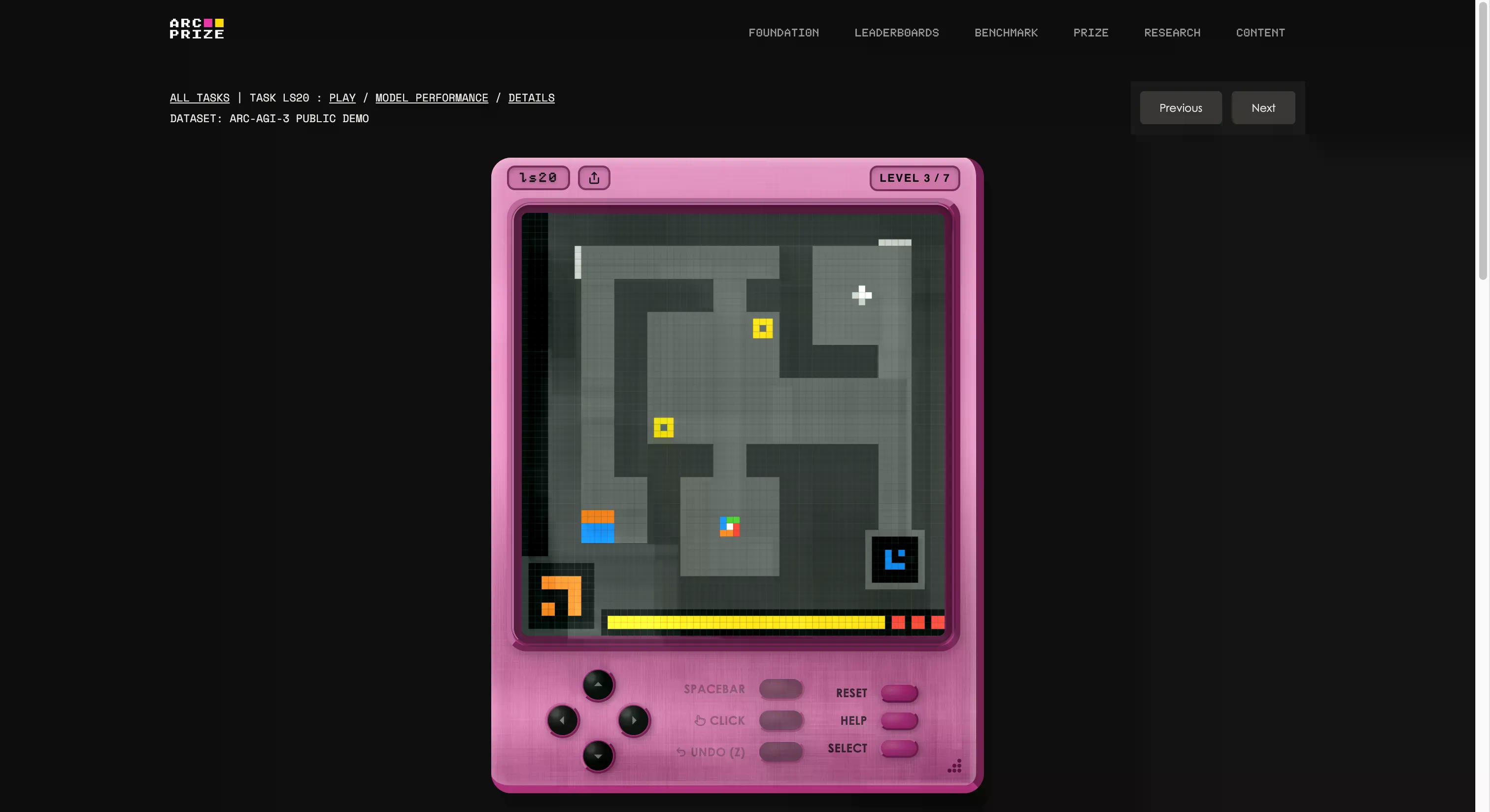
Jest to również najjaśniejszy przykład tego, co oznacza litera „G” w skrócie AGI. Kiedy generalizujesz, jesteś w stanie tworzyć nową wiedzę (jak działa dziwna gra) bez wcześniejszego szkolenia w tym zakresie.
Poprzednie wersje ARC testowały statyczne zagadki wizualne – pokaż wzór, przewidź następny. Na początku były trudne. Potem laboratoria rzuciły na nie moc obliczeniową i trening, aż benchmarki stały się praktycznie martwe. ARC-AGI-1, wprowadzony w 2019 roku, uległ treningowi w czasie testowania i modelom rozumowania. ARC-AGI-2 utrzymał się około roku, zanim Gemini 3.1 Pro osiągnął 77,1%. Laboratoria bardzo dobrze sobie radzą z nasycaniem benchmarków, na których mogą trenować.
Wersja 3 została zaprojektowana specjalnie, aby temu zapobiec. Z 110 ze 135 środowisk utrzymywanych w tajemnicy – 55 częściowo prywatnych do testowania API, 55 całkowicie zablokowanych dla konkursu – nie ma zestawu danych do zapamiętania. Nie można brutalnie przedrzeć się przez nową logikę gry, której nigdy wcześniej nie widziano.
Punktacja również nie jest zero-jedynkowa. ARC-AGI-3 wykorzystuje to, co fundacja nazywa RHAE – Względną Wydajnością Akcji Człowieka. Podstawą jest drugi najlepszy wynik człowieka za pierwszym razem. AI, która wykonuje dziesięć razy więcej akcji niż człowiek, uzyskuje 1% dla tego poziomu, a nie 10%. Formuła podwaja karę za nieefektywność. Błądzenie, cofanie się i zgadywanie drogi do odpowiedzi jest surowo karane.
Najlepszy agent AI w miesięcznym podglądzie deweloperskim uzyskał 12,58%. Graniczne modele LLM, testowane przez oficjalne API, bez niestandardowych narzędzi, nie były w stanie przekroczyć 1%. Zwykli ludzie rozwiązali wszystkie 135 środowisk bez wcześniejszego szkolenia i instrukcji. Jeśli to jest poprzeczka, to obecna generacja modeli jej nie pokonuje.
Istnieje tu jedna prawdziwa debata metodologiczna. Raport ARC podaje, że niestandardowa uprząż stworzona na Duke'u podniosła wynik Claude'a Opus 4.6 z 0,25% do 97,1% w pojedynczym wariancie środowiska o nazwie TR87. Nie oznacza to, że Claude uzyskał 97,1% w całym ARC-AGI-3; jego oficjalny wynik benchmarku pozostał na poziomie 0,25%, ale zmiana jest warta odnotowania.
Oficjalny benchmark dostarcza agentom kod JSON, a nie wizualizacje. Jest to albo wada metodologiczna, albo demonstracja, że dzisiejsze modele lepiej przetwarzają informacje przyjazne dla człowieka niż surowe dane strukturalne. Fundacja Cholleta uznała tę debatę, ale nie zmienia formatu.
„Percepcja treści ramki i format API nie są czynnikami ograniczającymi wydajność modeli granicznych w ARC-AGI-3” – czytamy w raporcie. Innymi słowy, wydaje się, że odrzucają pomysł, iż modele zawodzą, ponieważ „nie widzą” zadań prawidłowo, argumentując zamiast tego, że percepcja jest już wystarczająca – a prawdziwa luka leży w rozumowaniu i generalizacji.
Sprawdzenie rzeczywistości AGI nastąpiło w tygodniu, kiedy machina szumu działała na pełnych obrotach. Poza komentarzem Huanga, Arm nazwał swój nowy chip do centrów danych „AGI CPU”. Sam Altman z OpenAI powiedział, że „zasadniczo zbudowali AGI”, a Microsoft już promuje laboratorium skupione na budowaniu ASI: ewolucji tego, co nastąpi po osiągnięciu AGI. Termin ten jest rozciągany, aż zdaje się oznaczać wszystko, co jest komercyjnie wygodne.
Stanowisko Cholleta jest prostsze. Jeśli zwykły człowiek bez instrukcji potrafi to zrobić, a twój system nie, to nie masz AGI – masz bardzo drogie autouzupełnianie, które potrzebuje dużo pomocy.
ARC Prize 2026 oferuje 2 miliony dolarów w trzech ścieżkach konkursowych, wszystkie hostowane na Kaggle. Każde zwycięskie rozwiązanie musi być otwarte. Zegar tyka, a w tej chwili maszyny nawet się nie zbliżają.