

向世界上最先進的五個AI系統詢問某個陳述是否屬實,結果有三分之二的機率,至少有一個系統會給出不同的答案。這是Lenz Research的研究員Kosta Jordanov本月發表的一項新研究的發現。
該研究讓GPT-5.4、Claude Opus 4.7、Gemini 3 Pro、帶有搜尋功能的Gemini 3 Pro和Sonar Pro處理相同的1,000個由實際使用者提交的真實世界事實查核主張。這些模型必須從四個標籤中選擇一個:真實、大部分真實、誤導性或虛假。
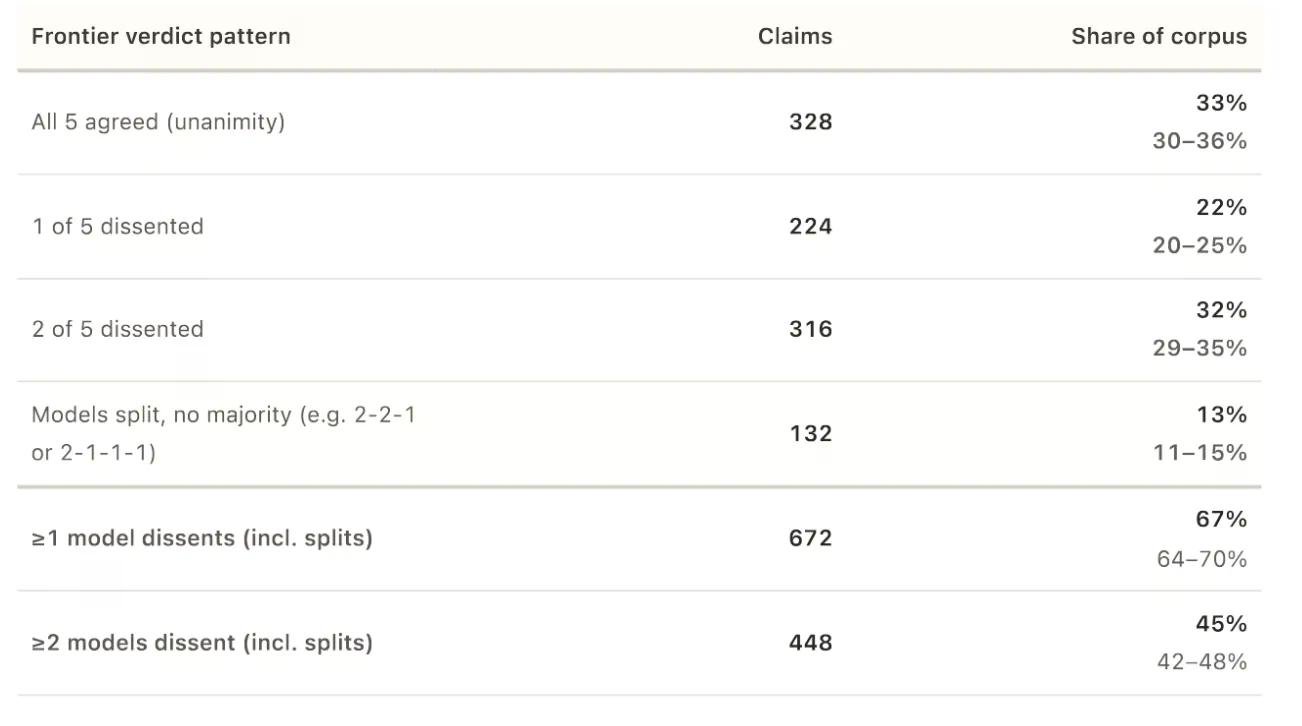
在1,000個主張中,有672個至少一個模型與多數意見產生分歧。其中有34%的案例分歧嚴重:一個模型認為主張是真實的,而另一個則認為是虛假的。
「這些並非帶有公開答案鍵的基準項目——它們是真實用戶提交給事實查核平台以供驗證的主張,」研究報告寫道。「每個主張只有一個判斷結果是正確的,因此面板之間任何分歧都意味著至少有一個模型的判斷,在這種四分類標準下,是標籤不一致的。」
此前關於AI幻覺(hallucination)的研究顯示,聊天機器人會憑空捏造事實。那是一個問題。而這是一個不同的問題。這些模型不一定是在憑空創造內容,它們只是對於相同材料的基本事實判斷無法達成一致。
該研究採用了一種讓AI公司難以解釋的設置。研究人員沒有從標準測試集(這類測試集通常會洩漏到訓練數據中)中提取主張,而是使用了真實用戶提交給Lenz事實查核平台的主張。「這些主張大部分不太可能出現在任何帶有黃金標準標籤的訓練語料庫中——沒有規範的答案鍵可供模式匹配,也沒有基準排行榜可供參考,」論文指出。
用於衡量一致性的統計指標,稱為Krippendorff’s alpha,得分為0.639,其中1.0代表完美一致,0代表隨機機會。研究稱這表示「非輕微但有限的一致性」。「模型的判斷是結構化的,而非隨機的,但一致性不足以將該面板視為單一可互換的判斷者,」研究人員指出。研究人員普遍認為低於0.8的分數是弱的。
當所有五個模型都達成一致時(這僅發生在1,000個主張中的328個),它們幾乎從未同意某事是誤導性或大部分真實的。只有四個主張獲得了「誤導性」的一致判斷。沒有任何主張獲得「大部分真實」的一致判斷。
研究人員提供了AI模型分歧最大的範例主張,其中包括「世界銀行在奈及利亞的活躍投資組合在2025年達到超過164億美元。」ChatGPT 5.4稱其為「大部分真實」,而Gemini 3 Pro稱其為「虛假」,其姊妹模型Gemini 3 Pro + Search則將其評為「誤導性」。
在另一個範例中,模型被提供了以下主張:「唐納德·川普表示,應海灣盟友的要求,對伊朗的襲擊被推遲了。」GPT-5.4稱其為虛假,Claude Opus 4.7稱其為大部分真實,Gemini 3 Pro稱其為虛假,而Gemini 3 Pro + Search則將其評為真實。
研究人員發現:「評審團在明確的判斷上趨於一致;分歧發生在中間地帶。」一致性只發生在極端情況:主張要麼絕對真實,要麼絕對虛假。
這很重要,因為人們越來越多地求助於AI系統進行事實查核。如果您將新聞文章中的主張貼到ChatGPT、Claude或Gemini中,您可能會得到三個不同的答案。您會信任哪一個?
AI公司喜歡告訴您它們的模型越來越準確。它們發布基準分數,顯示穩定的進步。但Lenz的研究測試了這些模型在真實人類會爭論的、複雜模糊的主張上的表現——結果發現這些模型也會爭論不休。
這份論文小心地指出了這一點:「多數前沿模型並非事實真相。多數判斷有時是錯誤的;個別持異議的模型有時是正確的。我們將多數意見用作衡量分歧的結構性參考點,而不是作為正確性的替代品。」
這些數字背後隱藏著一個更深層次的問題。當模型意見不一致時,至少有一個必須是錯誤的——該研究稱模型的判斷「在這種四分類標準下是標籤不一致的」。沒有決策機制,也沒有上訴法院。最近關於AI可靠性的報導也發出了類似的警告。
在所有五個模型達成一致的328個主張中,沒有一個獲得一致的「大部分真實」判斷。細微差別的分類完全被清空。如果AI模型只能在極端情況下達成共識,那麼它們還能被信任作為事實查核工具嗎?
