

據《金融時報》週四報導,Anthropic 已派遣約六名工程師進駐美國國家安全局 (National Security Agency),協助部署其最強大的 AI 模型 Mythos,用於攻擊性網路行動。
這些工程師是前線部署人員,負責為特定應用客製化模型。一位消息人士告訴《金融時報》,這對於滲透中國和伊朗等國家的網路可能會有幫助。
這些工程師是否參與了實際行動尚未證實。可以確定的是:Mythos 是 Anthropic 因濫用風險而拒絕公開發布的模型。該公司透過「玻璃之翼計畫」(Project Glasswing) 將其限制於經審查的合作夥伴使用,該計畫是一個受限聯盟,包括微軟、蘋果和亞馬遜。
Anthropic 也在起訴五角大廈。二月下旬,國防部長 Pete Hegseth 將該公司列為供應鏈風險——這個標籤歷史上是為華為等外國對手保留的——此前一項 2 億美元的合約告吹。症結點是:Anthropic 拒絕讓美國國防部將 Claude 用於全自動武器或國內大規模監控。而與美國國家安全局的合約則不受該禁令限制。
加州一名法官阻止了這項黑名單,認為這明顯是違反第一修正案的報復行為。華盛頓特區上訴法院拒絕了 Anthropic 在訴訟進行期間停止黑名單的請求。據《金融時報》報導,美國國家安全局在此期間一直使用 Mythos。
如何阻止會自我建構的 AI
在國家安全局消息傳出的同一天,Anthropic 內部研究機構發表了《當 AI 自我建構》(When AI Builds Itself),探討了 Claude 在自動化自身開發方面的進展。在報告中,該公司基本上主張在全球 AI 軍備競賽中實施全球暫停——甚至將其比作冷戰時期美國和俄羅斯簽訂的核條約。
為了理解原因,該公司提供了以下背景資訊:
Claude 現在編寫 Anthropic 產品程式碼庫中超過 80% 的程式碼——這比 2025 年初 Claude Code 推出之前的個位數大幅增加。工程師每天發布的程式碼量約是 2024 年的八倍。
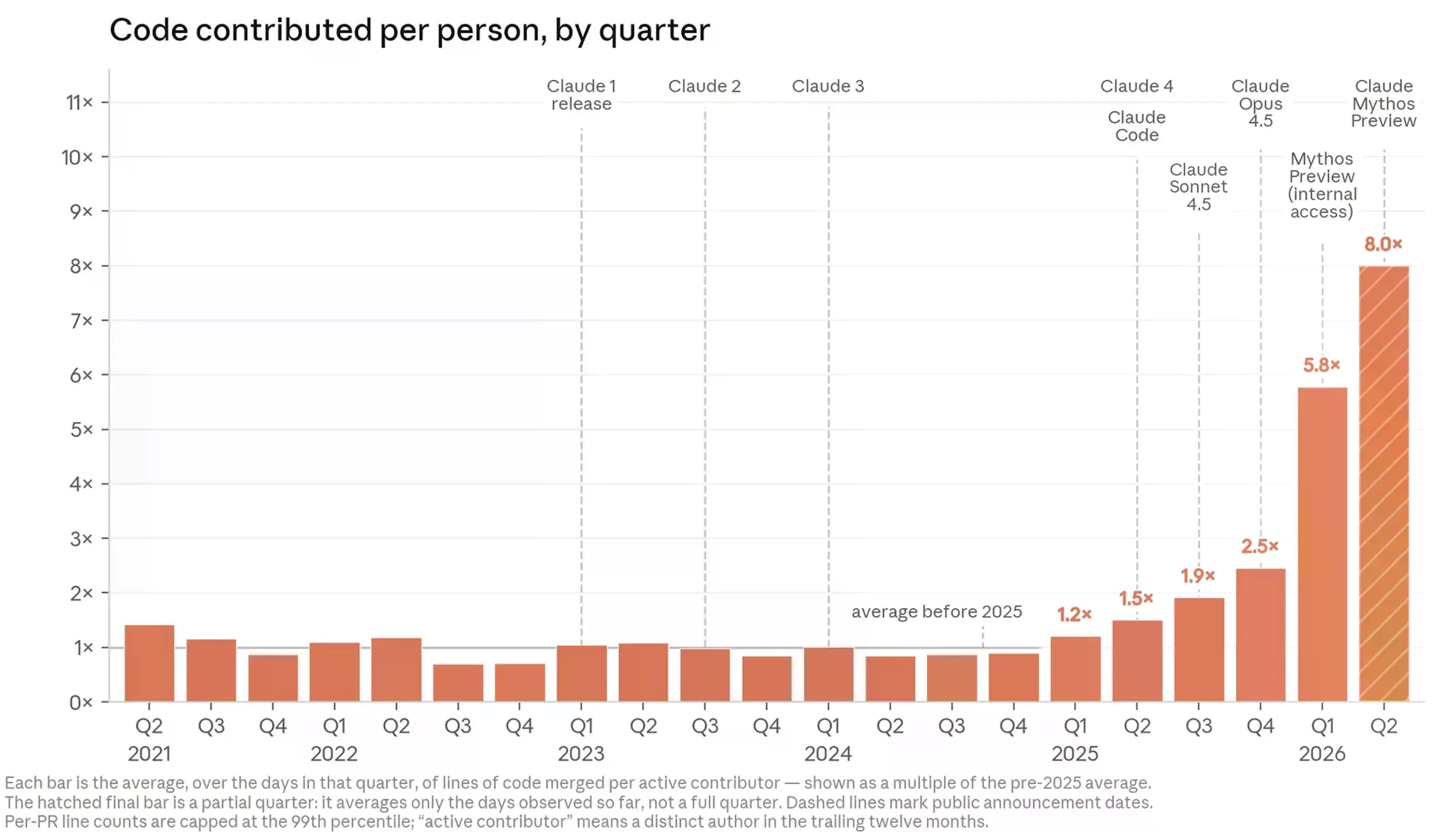
報告作者——Anthropic 研究所負責人 Marina Favaro 和共同創辦人 Jack Clark——認為這一發展軌跡正走向他們所稱的遞歸式自我改進:AI 系統自主設計、建構和訓練它們的繼任者,而人類在每個步驟中扮演的角色越來越少。
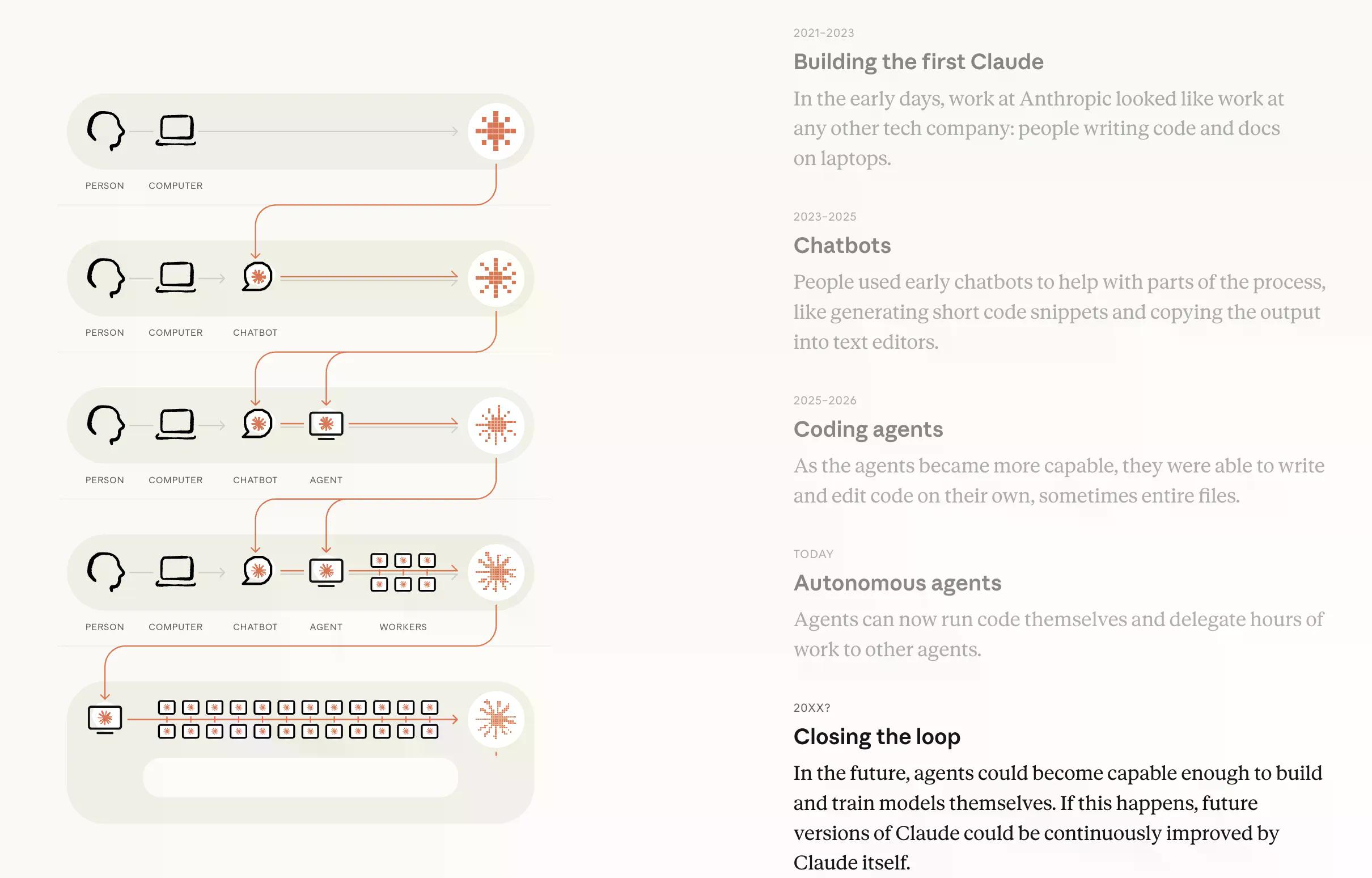
在視覺呈現中,研究人員展示了一個時間線,其中 AI 在工作中的第一種使用方式是人類提示電腦以獲得結果,隨著自動化的增加,最終將由 AI 代理提示子代理,直到結果達成,無需人類參與。
他們引用最明確的數據點是:四月份,Claude 代理被交予一個開放的 AI 安全問題——一個較弱的模型是否能可靠地監督一個較強的模型——並讓其自行運行。兩名人類研究人員花了大約一週的時間,彌補了模型之間 23% 的性能差距。而這些代理在 800 個累積計算小時內,彌補了 97% 的差距。人類設定了問題。代理設計了所有實驗。這是 Claude 首次展現研究判斷力,而不僅僅是執行他人指定的任務,這是一個已發表的案例。
這正是 Anthropic 擔心會跨越的界線。一旦 AI 選擇哪些實驗值得運行——而不僅僅是運行它們——人類將失去開發循環中最後一個有意義的角色。當今模型中微小的偏差可能會在自我改進的世代中累積,直到無人能糾正它們。
他們提出的解決方案是可驗證的全球暫停——多個前沿實驗室同時停止,並獨立驗證每個實驗室確實停止。Anthropic 表示他們將會加入。他們承認,單方面的放緩只會讓領先地位拱手讓給那些繼續前進的人。
我們以前看過這部電影。建造 AI 的實驗室,同時也是警告 AI 危險的實驗室。然而,AI 是這個十年最有利可圖的業務,所以沒有人願意停止——甚至那些警告 AI 危險的人也不例外。
早在 2023 年,一百多位 AI 研究領域的知名人士簽署了一封公開信,呼籲全球共同努力,以減輕 AI 發展本身所帶來的滅絕風險。在此幾個月前,另一封公開信要求 OpenAI 暫停 ChatGPT 的進展,因為其具有危險性。
2023 年公開信之後,沒有人停止。OpenAI 沒有,Anthropic 也沒有。五角大廈將 Claude 從其系統中移除的截止日期落在八月,大約在 Anthropic 預計將其財務狀況公開的 IPO 同一時間。
