

人工智慧個人助理的賣點一直以來都相同:讓代理存取你的數位生活,然後它會處理其餘一切。你的電子郵件、你的行事曆、你的筆記、你的裝置—所有這些。你的 AI 知道。你的 AI 行動。你休息。
來自華為技術、北京理工大學、北京大學和中國科學院的研究人員剛剛建立了一個基準測試,以驗證這是否真的屬實。劇透一下:並非如此。
Claw-Anything 從三個維度同時評估 AI 代理:涵蓋三個月以上模擬用戶活動的長週期事件流、每個任務平均 10.1 個相互依賴的後端服務,以及跨 CLI Linux 環境和 GUI Android 環境的多裝置互動。
每個任務的平均上下文視窗為 191,700 字。大多數現有基準測試的範圍在 1,700 到 12,000 之間。這不是一個小差距,而是完全不同的問題。這也更貼近真實生活感受,而不是標準化的超特定基準測試。
你的 AI 不知道發生了什麼
該基準測試以 pass@1 計分—即代理在第一次嘗試時正確完成任務的機率,不允許重試。一個任務可能會要求代理交叉比對幾週前找到的產品價格警報、檢查用戶行事曆以尋找相關約會,並透過手機對兩者採取行動。另一個任務可能會要求它從筆記、電子郵件對話和 Slack 中提取近期工作,然後從頭開始製作一份簡報。
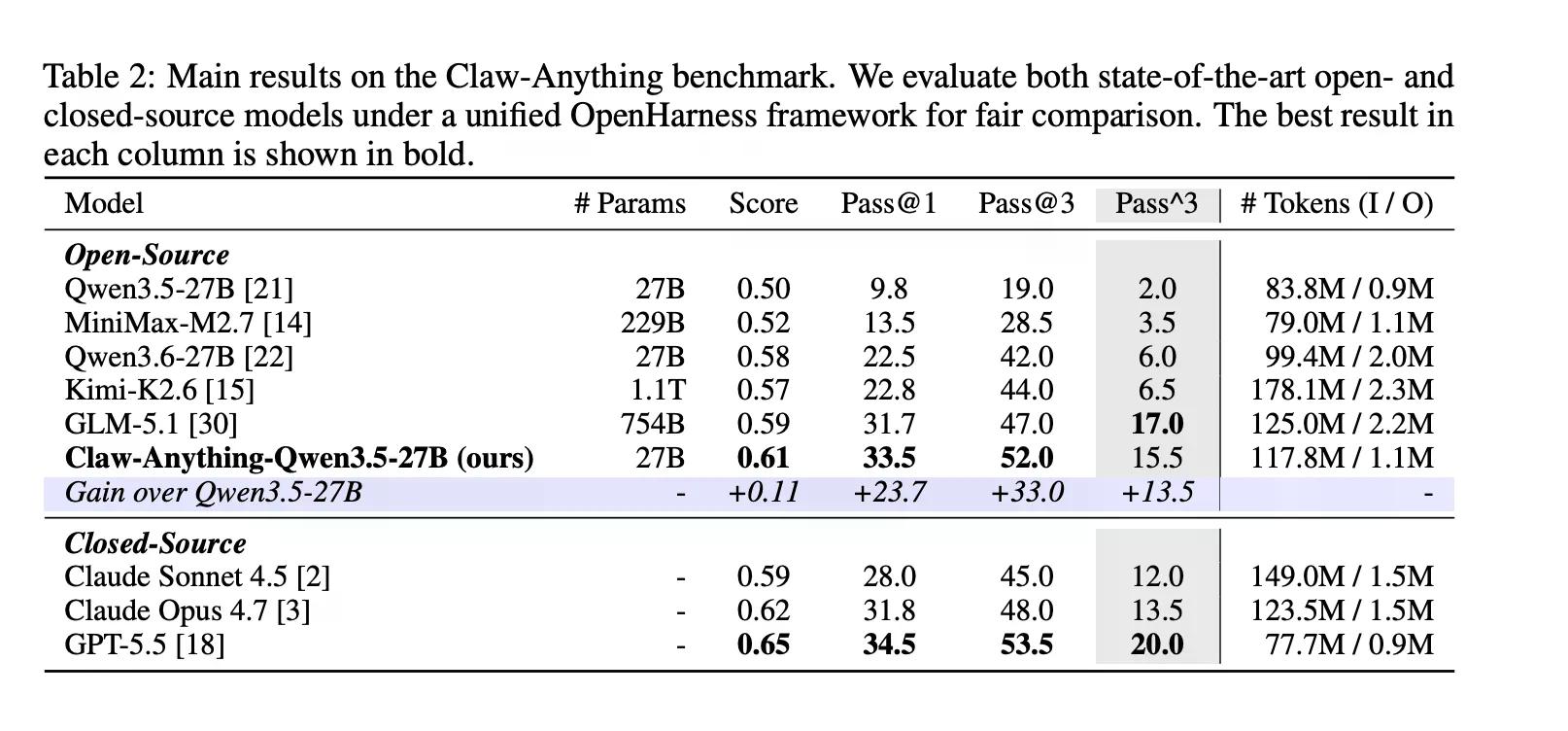
這些都是人們實際要求助理完成的事情。結果發現,AI 在這些方面表現不佳。根據 Decrypt 先前的報導,GPT-5.5 是 OpenAI 最好的模型,專為具備代理能力、長週期任務而設計。它的得分為 34.5%。
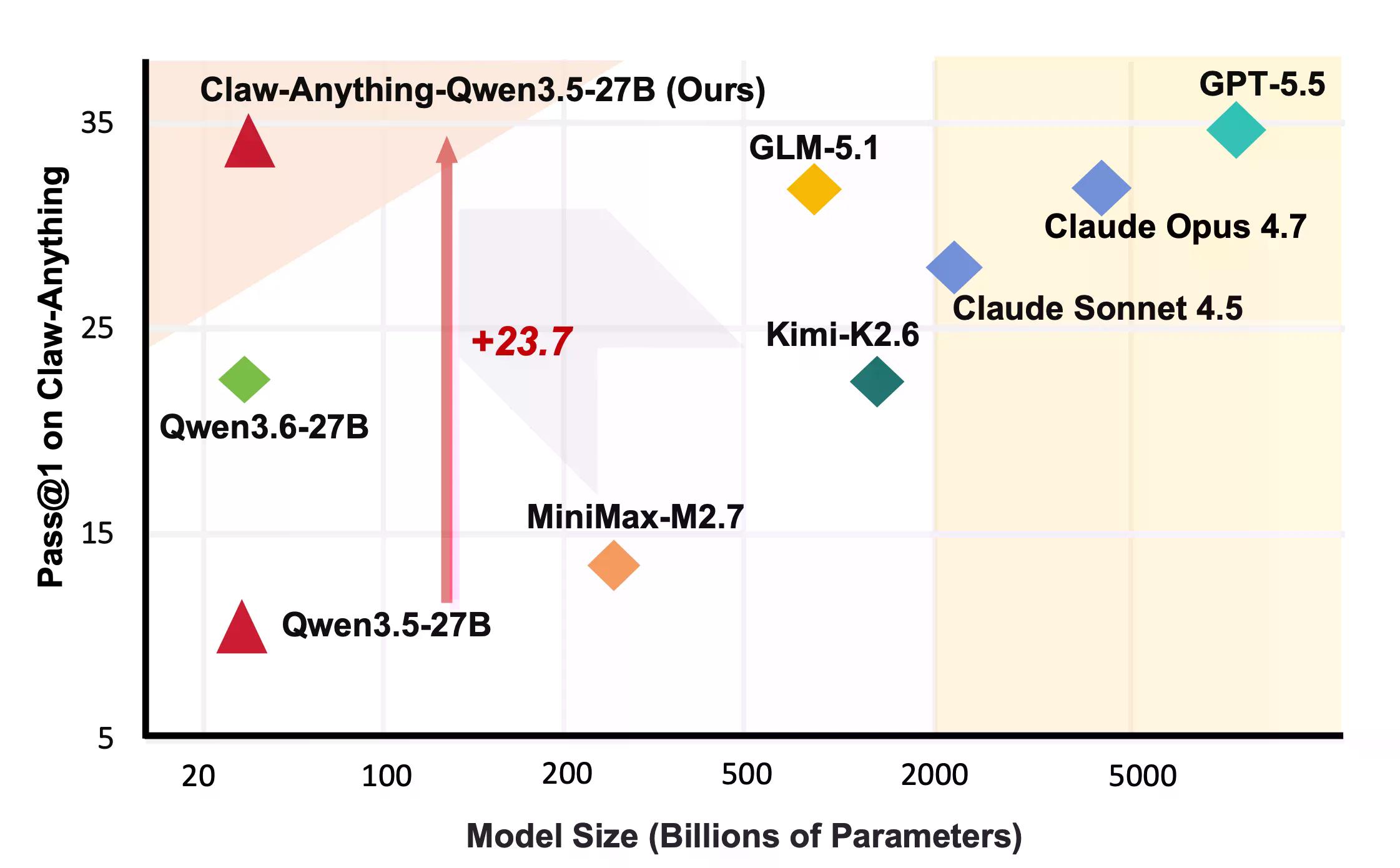
「目前的模型即使在獲得用戶數位世界的更廣泛存取權限時,仍然不可靠,」Claw-Anything 論文中寫道。一些在其他基準測試中表現出色的模型,在此次測試中得分進一步下降。
該基準測試還單獨評估主動協助能力,意指代理在未被要求的情況下發現需求並採取行動。大多數基準測試並未檢測這一點。Claw-Anything 則有,且差距明顯:代理在反應性任務上得分 25.9%,而在主動性任務上僅得分 6.7%。
為什麼大多數基準測試沒有告訴你這一點
研究人員提出了一個尖銳的論點:現有的基準測試將 AI 代理視為桌面整潔的任務解決者。Claw-Anything 則將它們視為被丟進混亂現實生活中的個人助理—存在無關事件、衝突信號和數月累積的雜訊。代理必須先找出哪些是相關的,然後才能做任何有用的事情。
消融實驗結果使得多服務依賴性特別清晰。當執行跨服務任務所需的工具被移除時,成功率幾乎降至零,因為大多數任務需要代理跨多個後端而非單一後端檢索資訊並採取行動。
這在 AI 評估中並非一個新類型的問題。OpenAI 在今年稍早宣布 SWE-bench 被污染,因為在一個更不易洩漏的版本上,分數從大約 70% 驟降至 23%。那關乎資料衛生。而這則關乎更根本的問題—基準測試是否甚至提出了正確的問題。
從建設性的一面來看,該團隊發布了生成基準測試的管道,以及 2,000 個訓練環境。透過對 1,500 個成功的代理軌跡進行 Qwen3.5-27B 微調,pass@1 提高了 23.7%—足以擊敗排行榜上包括 Claude Sonnet 在內的多個閉源模型。
研究人員將跨服務協調確定為該領域基準測試的主要剩餘挑戰。該資料集已發布在 Hugging Face 上,程式碼則可在 GitHub 取得。
