

شش هفته. این مدت زمانی است که Anthropic طول کشید تا از Opus 4.7 به Opus 4.8 برسد.
مدل جدید در تستهای بنچمارک سریعتر و هوشمندتر است و با مجموعهای از ویژگیهای جدید عرضه میشود—اما قیمت آن تغییری نکرد: همانند قبل، ۵ دلار به ازای هر میلیون توکن ورودی و ۲۵ دلار به ازای هر میلیون توکن خروجی است.
همچنین یک حالت سریع (fast mode) وجود دارد که همین مدل را با سرعت ۲.۵ برابر برای ۱۰ دلار ورودی و ۵۰ دلار خروجی به ازای هر میلیون اجرا میکند. Anthropic میگوید که این نرخ اکنون سه برابر ارزانتر از هزینه حالت سریع در مدلهای قبلی است، که راه خوبی برای گفتن این است که قبلاً بسیار گرانتر بوده است.
SWE-bench Pro احتمالاً مهمترین بنچمارک برای مشاهده و درک میزان خوب بودن این مدل است. این بنچمارک اندازهگیری میکند که آیا یک هوش مصنوعی میتواند مسائل دشوار مهندسی نرمافزار چندزبانه را که از پایگاههای کد تولید واقعی گرفته شدهاند، حل کند – که به صورت درصدی از مسائل حل شده محاسبه میشود.
در آن تست، Opus 4.8 به ۶۹.۲% رسید، که از ۶۴.۳% برای Opus 4.7 بیشتر است. GPT-5.5 متعلق به OpenAI امتیاز ۵۸.۶% و Gemini 3.1 Pro متعلق به گوگل با ۵۴.۲% عقب ماندند. برای مدلی با همان نقطه قیمتی، این یک جهش معنیدار است.
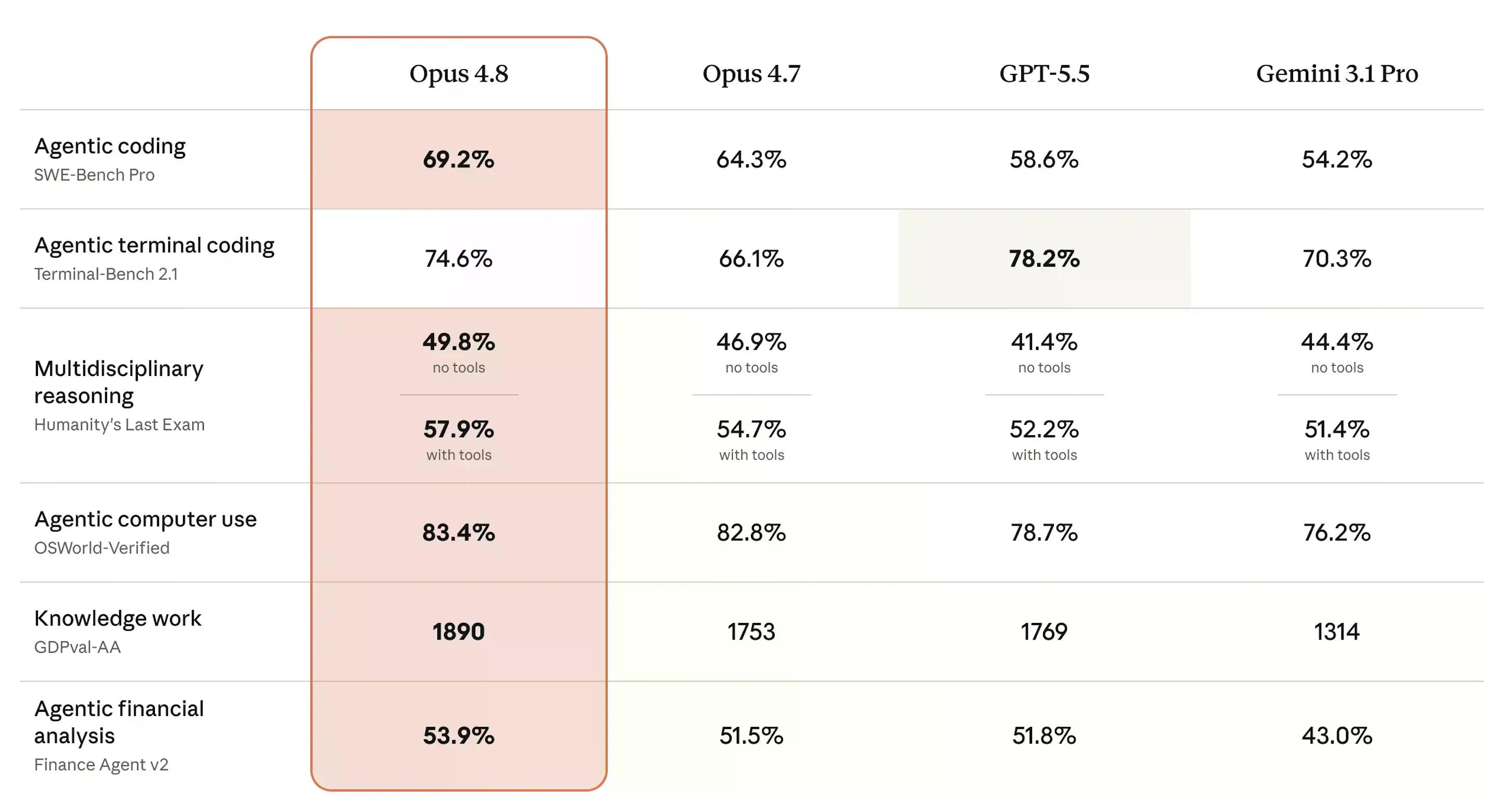
در "آخرین آزمون بشریت" (Humanity's Last Exam) – سوالات سطح متخصص در دهها رشته دانشگاهی که به صورت درصد صحیح امتیازدهی میشوند – Opus 4.8 بدون ابزار به ۴۹.۸% و با ابزار به ۵۷.۹% رسید که از هر سه رقیب پیشی گرفت. OSWorld-Verified که وظایف استفاده از کامپیوتر در دنیای واقعی مانند پیمایش رابطهای کاربری نرمافزار را آزمایش میکند، ۸۳.۴% امتیاز آورد که کمی از امتیاز ۸۲.۸% Opus 4.7 فراتر رفت.
تنها باخت: Terminal-Bench 2.1 که عملکرد هوش مصنوعی را در وظایف خط فرمان اندازهگیری میکند. GPT-5.5 با ۷۸.۲% پیشتاز است، در حالی که Opus 4.8 امتیاز ۷۴.۶% را کسب کرد – که بهتر از ۶۶.۱% Opus 4.7 و جلوتر از ۷۰.۳% Gemini است، اما جایگاه دوم در نهایت باز هم باخت محسوب میشود.
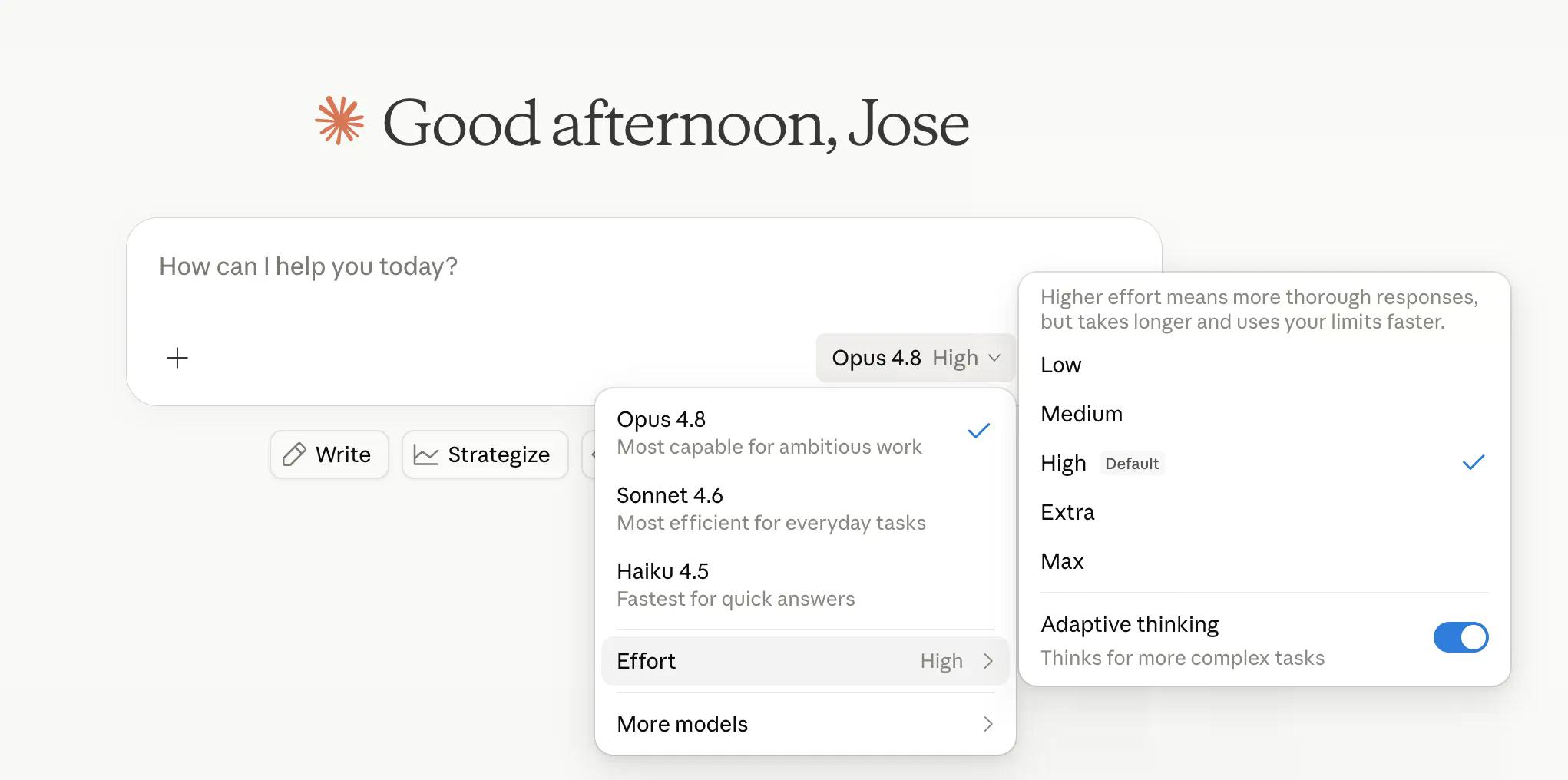
Anthropic اکنون به کاربران اجازه میدهد تا میزان تفکر مدل را کنترل کنند. "High" (بالا) تنظیم پیشفرض است و اکثر وظایف را به خوبی انجام میدهد، در حالی که "Extra" (فوقالعاده) – که در داخل Claude Code "xhigh" نامیده میشود – محاسبات بیشتری را برای مسائل دشوارتر صرف میکند. "Max" (حداکثر) نهایت کارایی است. "Low" (پایین) و "Medium" (متوسط) توکنهای کمتری را به همان وظیفه اختصاص میدهند و در ازای دقت، در زمان صرفهجویی میکنند.
کنترل تلاش (effort control) در کنار انتخابگر مدل در claude.ai و Cowork، برای همه برنامهها در دسترس است. Anthropic میگوید حالت پیشفرض "high" تقریباً از همان توکنهای پیشفرض Opus 4.7 استفاده میکند اما با نتایج بهتر – که هم مهندسی چشمگیر و هم پیامرسانی خوب است، و احتمالاً هر دو.
همچنین مهم است به یاد داشته باشید که توکنایزر جدید Anthropic برای Opus، توکنهای بیشتری را برای هر کار استفاده میکند. بنابراین کاربران کلاد به ناچار برای انجام کارها، هزینه بیشتری را صرف خواهند کرد، اگر Opus را به جای Claude Sonnet انتخاب کنند – مدلی با قابلیتهای کمتر، اما احتمالاً برای کارهای روزمره و مسائل پیچیدهای که به سطح علم پیشرفته یا کدنویسی نمیرسند، کافی است.
محدودیتهای نرخ (Rate limits) در Claude Code نیز برای جذب مصرف توکن بالاتر که تنظیمات Extra و Max ایجاد میکنند، افزایش یافتند.
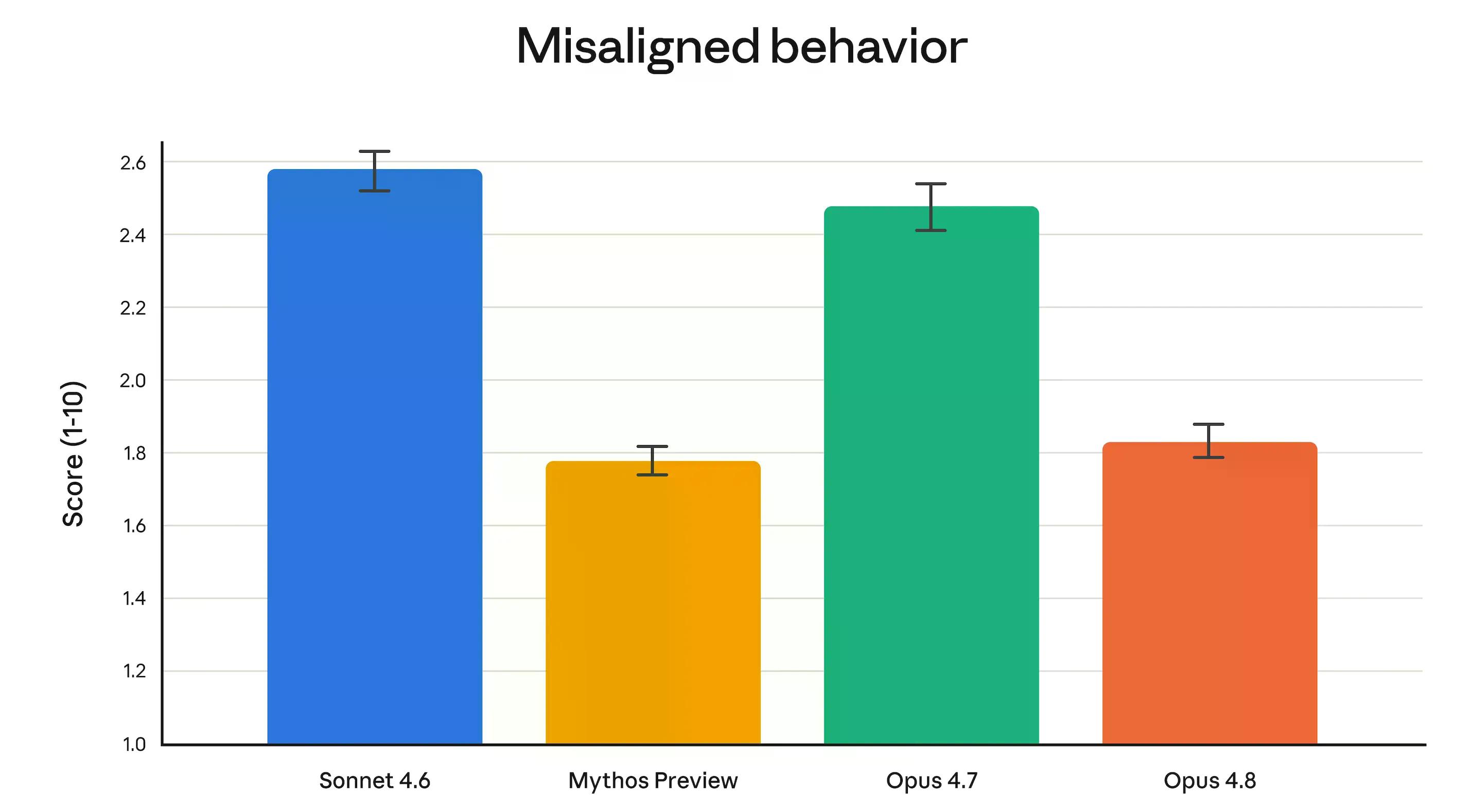
تیم همسویی Anthropic گفت که Opus 4.8 "در اندازهگیریهای ما از ویژگیهای اجتماعی مانند حمایت از خودمختاری کاربر و عمل به نفع کاربر، به اوجهای جدیدی میرسد." به طور مشخصتر: نرخهای فریب و نرخهای همکاری در سوءاستفاده به طور قابل توجهی کمتر از Opus 4.7 بود و با Claude Mythos Preview – مدل محدودشدهتر Anthropic – قابل مقایسه است.
Opus 4.8 همچنین چهار برابر کمتر از 4.7 احتمال دارد که باگها را در کد خود بدون علامتگذاری نادیده بگیرد.
مقایسه Mythos نیازمند توضیح است. Mythos یک سطح کاملاً بالاتر از Opus است – Anthropic آن را "بزرگتر و هوشمندتر از مدلهای Opus ما" توصیف میکند. در حال حاضر تنها به صورت پیشنمایش وجود دارد و برای تعداد انگشتشماری از سازمانهای تأیید شده که از طریق Project Glasswing کارهای امنیت سایبری انجام میدهند، قابل دسترسی است.
موسسه امنیت هوش مصنوعی بریتانیا دریافت که این مدل میتواند "آخرینها" (The Last Ones)، یک شبیهسازی حمله شبکه شرکتی ۳۲ مرحلهای را که معمولاً تیمهای قرمز انسانی ۲۰ ساعت طول میکشند، به صورت خودکار تکمیل کند. به همین دلیل هنوز برای فروش نیست. Anthropic میگوید که تدابیر امنیتی سایبری قویتری در دست اقدام است و انتظار دارد مدلهای کلاس Mythos را "در هفتههای آینده" برای همه ارائه دهد.
همچنین امروز عرضه شده: جریانهای کاری پویا در Claude Code، در پیشنمایش تحقیقاتی. این ویژگی به Claude اجازه میدهد تا اسکریپتهای ارکستراسیون خود را بنویسد و زیرعاملهای موازی را در یک جلسه راهاندازی کند، خروجیهای آنها را تأیید کند و گزارش دهد – درست مانند کاری که هرمس مدتی است انجام میدهد.
جریانهای کاری پویا برای کاربران طرحهای Enterprise, Team و Max در دسترس هستند و Anthropic به صراحت اعلام کرده است که آنها توکنهای بسیار بیشتری را نسبت به یک جلسه استاندارد Claude Code مصرف میکنند.
قیمتگذاری ۵ دلار / ۲۵ دلار Anthropic در کنار کارهایی که چین اخیراً انجام داده، بسیار متفاوت به نظر میرسد.
DeepSeek V4 Pro هفته گذشته تخفیف ۷۵ درصدی خود را دائمی کرد: ۰.۴۳۵ دلار به ازای هر میلیون توکن ورودی و ۰.۸۷ دلار به ازای هر میلیون توکن خروجی. Xiaomi MiMo V2.5 Pro نیز با همین نرخها از طریق ارائهدهندگانی مانند OpenRouter فعالیت میکند.
حالت سریع Anthropic ۱۰ دلار برای ورودی و ۵۰ دلار برای خروجی به ازای هر میلیون هزینه دارد – گرانتر از خود Opus 4.8 استاندارد است، و تقریباً ۵۷ برابر بیشتر در هر توکن خروجی نسبت به DeepSeek V4 Pro. شرکتها پیش از این میلیونها دلار صرف پردازش (inference) روی مدلهای آمریکایی کردهاند. اگر با Opus به صورت گسترده کار کنید، ممکن است کسبوکارتان به سرعت به میلیونها دلار برسد.
پاسخ Anthropic به شکاف قیمتی، کیفیت و ایمنی است. در SWE-bench Pro، Opus 4.8 هر دو مدل چینی را شکست میدهد. در زمینه همسویی (alignment)، هیچ یک از آنها به بنچمارکهای منتشر شده Anthropic نزدیک نمیشوند.
این موارد در محیطهای تولیدی که یک مدل به آرامی با ورودیهای نامناسب همکاری میکند، یک خطر واقعی محسوب میشوند – صنایع تحت نظارت، کارهای حقوقی، و هر چیزی که در آن "به نظر خوب میآمد" یک گزارش قابل قبول پس از حادثه نیست. برای بقیه، نادیده گرفتن این شکاف دشوار است.
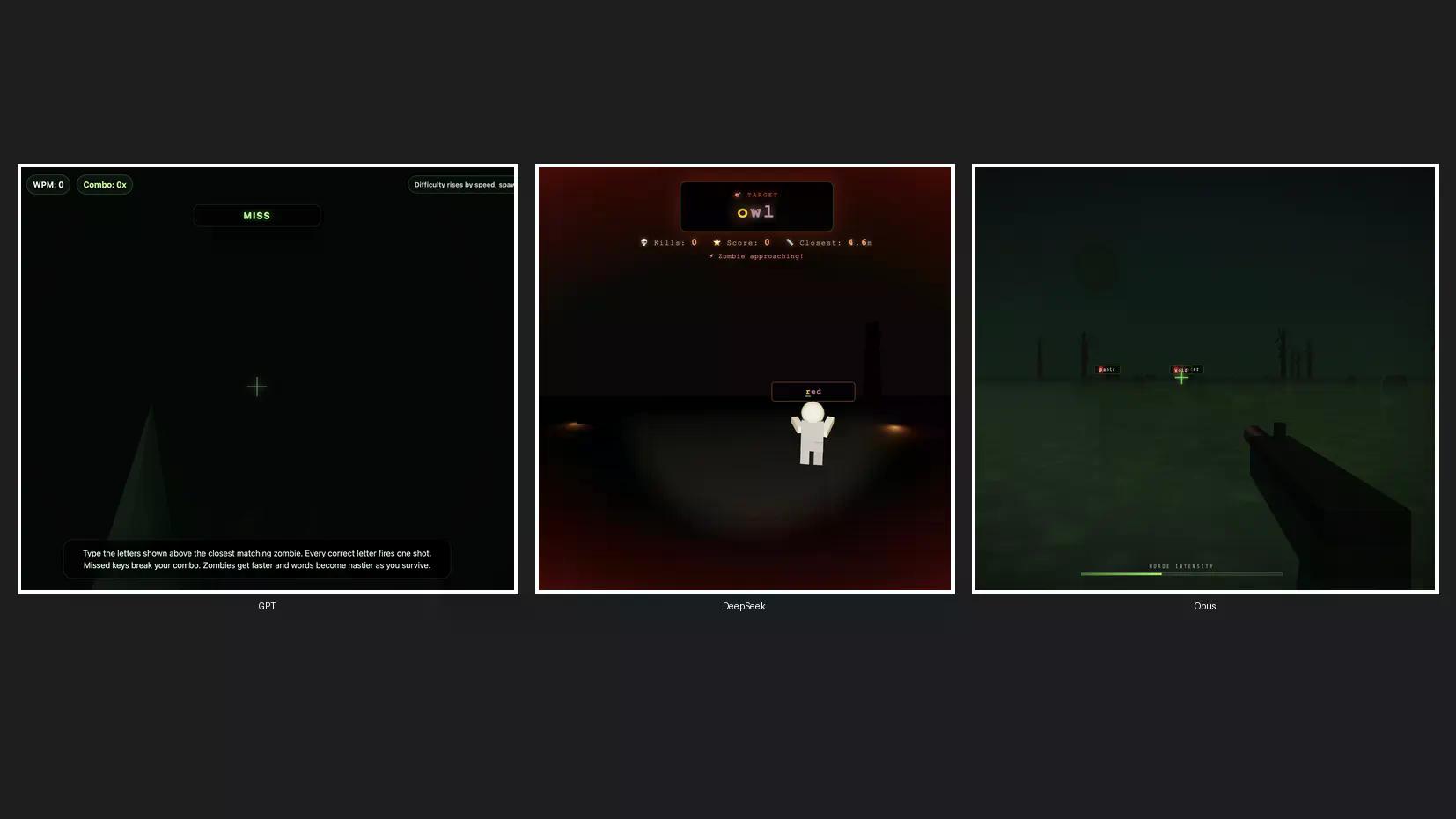
ما یک آزمایش کدنویسی سریع برای ساخت یک بازی زامبی سهبعدی انجام دادیم تا ببینیم Claude Opus 4.8 چگونه در برابر ChatGPT و DeepSeek، که مسلماً محبوبترین رقبای آن از آمریکا و چین هستند، قرار میگیرد. ما Opus 4.8 را روی حالت پیشفرض high، GPT-5.5 را روی high effort، و DeepSeek V4 Pro را روی high effort تنظیم کردیم – سه مدل، یک درخواست، بدون تلاش مجدد.
GPT-5.5 اول شد. بازی آن هیچ تصویر زامبی و جلوه صوتی نداشت. سریع بود، البته، اما کاملاً از هدف اصلی منحرف شد.
DeepSeek V4 Pro با حرکت ماوس، شخصیتهای زامبی واقعی، جلوههای صوتی، مکانیکهای قوی، و زیباییشناسی تمیز، در جایگاه دوم قرار گرفت. هیچ شکایتی در این زمینه وجود نداشت.
Opus 4.8 تقریباً سه برابر GPT-5.5 زمان برد، اما بهترین صفحه نمایش اولیه، بهترین طراحیهای زامبی، بهترین مکانیکهای بازی، و جلوههای صوتی قابل قبول را ارائه داد. کندترین بود، اما بهترین خروجی را داشت. با این حال، با توجه به شکاف قیمتی، احتمالاً این کافی نیست که استفاده از آن را نسبت به DeepSeek توجیه کند.
همه بازیها در پروفایل Itch.io ما در دسترس هستند. GPT-5.5 بازی Zombie Typing، Opus بازی Typing Dead، و DeepSeek v4 Pro بازی بدون نامی را تولید کرد که شما را مستقیماً وارد عمل میکند. بیایید آن را TypeSeek بنامیم.
یک بررسی مقایسهای کامل در راه است. در حال حاضر: Claude Opus 4.8 برای این نوع کارها بهتر از GPT-5.5 و Opus 4.7 کدنویسی میکند، با همان قیمتی که Anthropic از زمان 4.7 دریافت میکرده است. توسعهدهندگانی که قبلاً ۵ دلار برای هر میلیون توکن پرداخت میکردند، اکنون یک مدل بهتر را به صورت رایگان دریافت کردهاند.
