

六週。這是 Anthropic 從 Opus 4.7 進展到 Opus 4.8 所花費的時間。
這個新模型在基準測試中更快、更智能,並附帶一套新功能——但價格並未變動:輸入 token 每百萬 5 美元,輸出 token 每百萬 25 美元,與之前相同。
還有一個快速模式,能以 2.5 倍的速度運行相同的模型,輸入價格為 10 美元,輸出價格高達每百萬 50 美元。Anthropic 表示,現在這個費率比之前模型的快速模式便宜三倍,這是一種委婉的說法,表示它以前貴很多。
SWE-bench Pro 可能是最重要且能了解這個模型好壞的基準測試。它衡量 AI 是否能真正解決來自實際生產程式碼庫的困難多語言軟體工程問題——得分是通過問題的百分比。
在該測試中,Opus 4.8 達到 69.2%,高於 Opus 4.7 的 64.3%。OpenAI 的 GPT-5.5 得分 58.6%,Google 的 Gemini 3.1 Pro 則落後在 54.2%。對於同等價位的模型來說,這是一個顯著的提升。
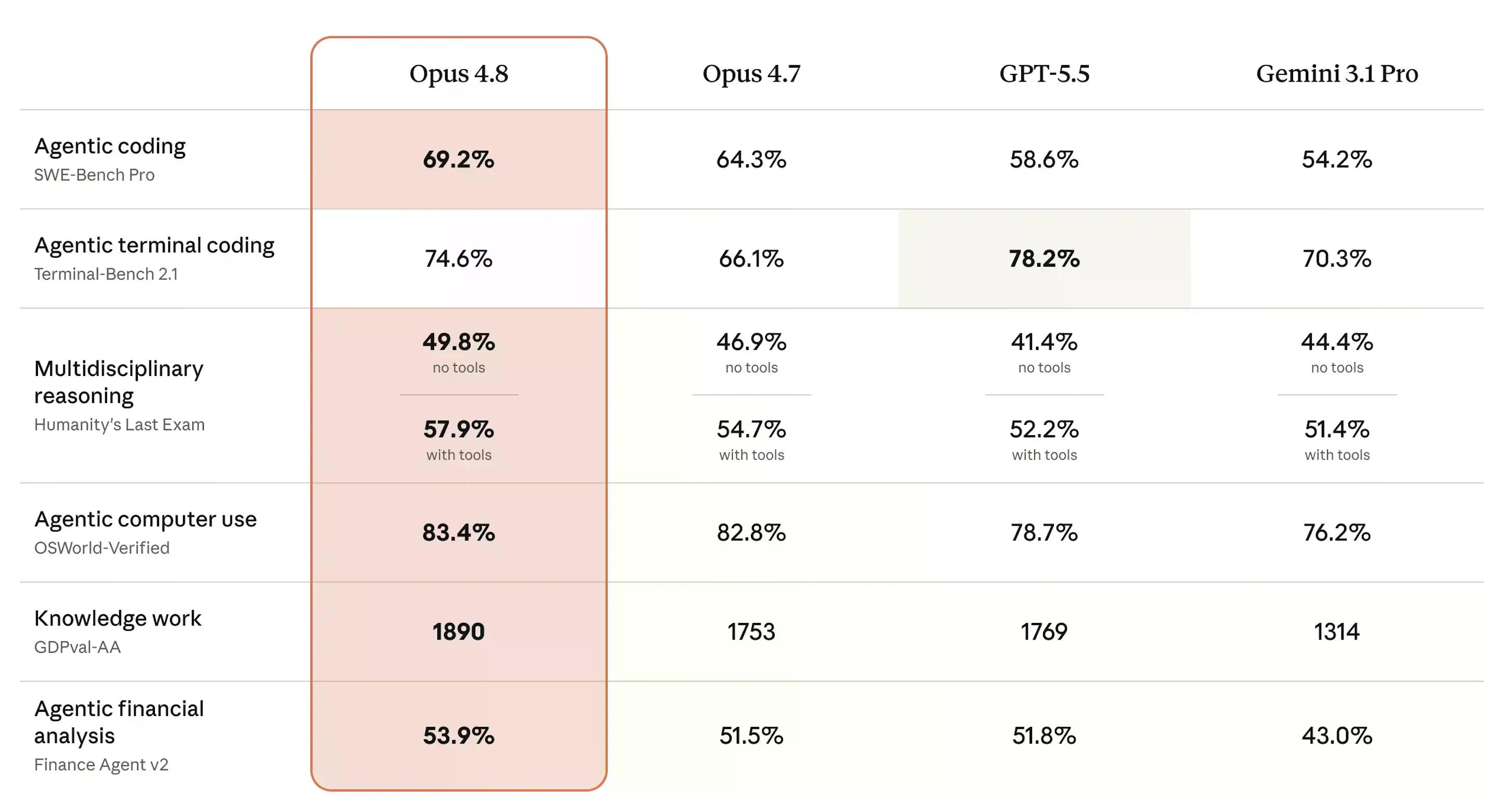
在「人類終極考驗」( Humanity's Last Exam)——針對數十個學術領域的專家級問題,以正確率百分比計分——Opus 4.8 在沒有工具的情況下達到 49.8%,使用工具則達到 57.9%,領先所有三個競爭對手。OSWorld-Verified 測試真實世界的電腦使用任務,例如導航軟體使用者介面,得分為 83.4%,略高於 Opus 4.7 的 82.8%。
唯一的失利是在 Terminal-Bench 2.1 上,該測試衡量 AI 在命令列任務上的表現。GPT-5.5 以 78.2% 領先,而 Opus 4.8 得分為 74.6%——優於 Opus 4.7 的 66.1% 並領先 Gemini 的 70.3%,但第二名終究還是輸了。
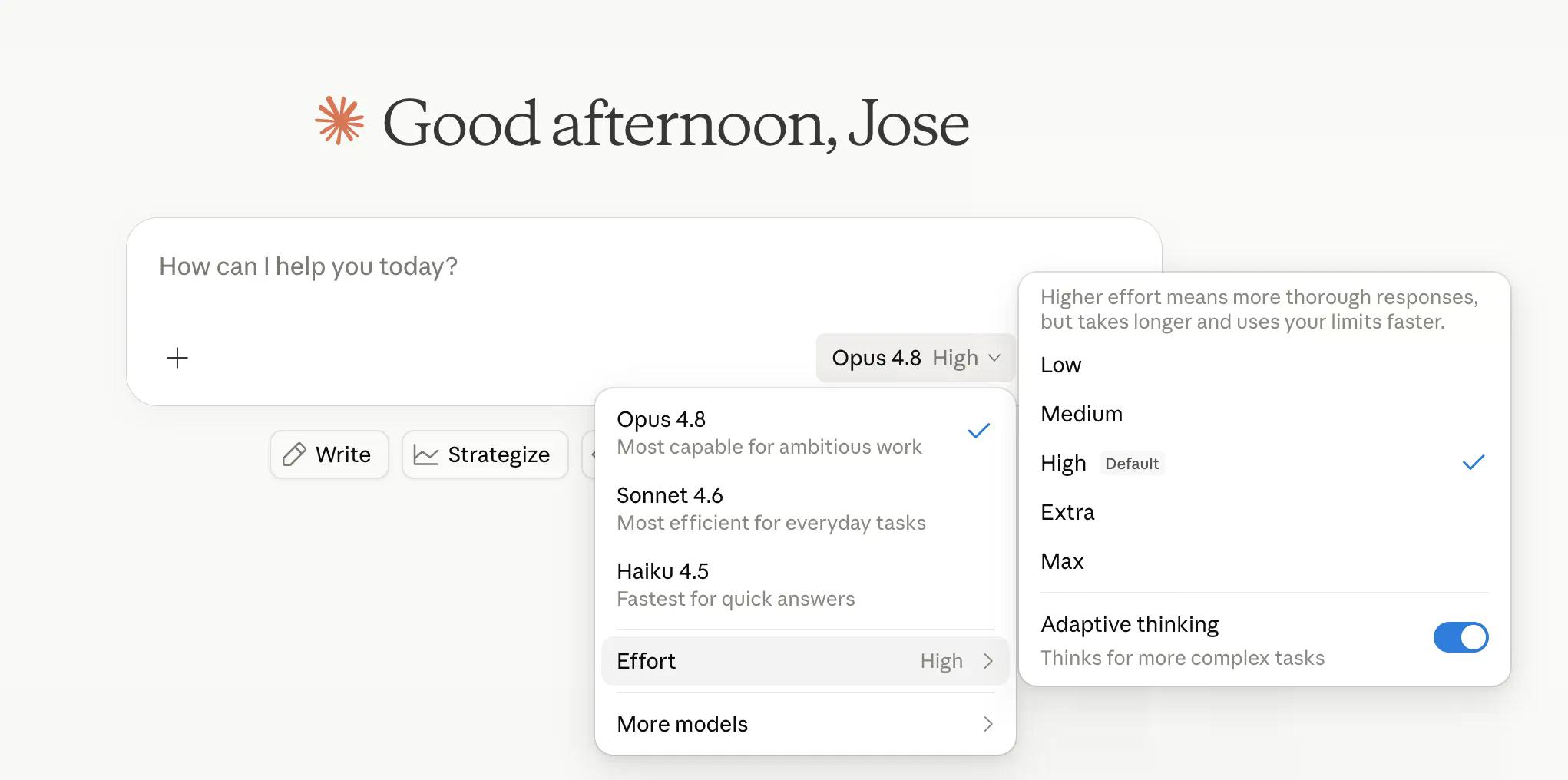
Anthropic 現在允許用戶控制模型「思考」的程度。「高(High)」是預設模式,能很好地處理大多數任務;而「特高(Extra)」——在 Claude Code 內部稱為「xhigh」——則為更困難的問題投入更多運算。「極高(Max)」則是最高階的選擇。「低(Low)」和「中(Medium)」則為相同的任務分配較少的 token,以時間換取精確度。
這個努力程度控制與 claude.ai 和 Cowork 中的模型選擇器並列,適用於所有方案。Anthropic 表示,預設的「高」模式使用的 token 量與 Opus 4.7 的預設模式大致相同,但結果更好——這既是令人印象深刻的工程成果,也可能是高明的行銷手法,很可能兩者皆是。
同樣重要的是,Anthropic 為 Opus 設計的新分詞器(tokenizer)在每個任務中會使用更多 token。因此,如果 Claude 用戶選擇 Opus 而非 Claude Sonnet,他們將不可避免地花費更多金錢才能完成任務——Claude Sonnet 雖然能力較弱,但對於日常任務和不需要達到前沿科學或編碼水平的複雜問題來說,可能已經足夠好用。
Claude Code 中的速率限制也已提高,以應對「特高」和「極高」設定所產生的更高 token 消耗。
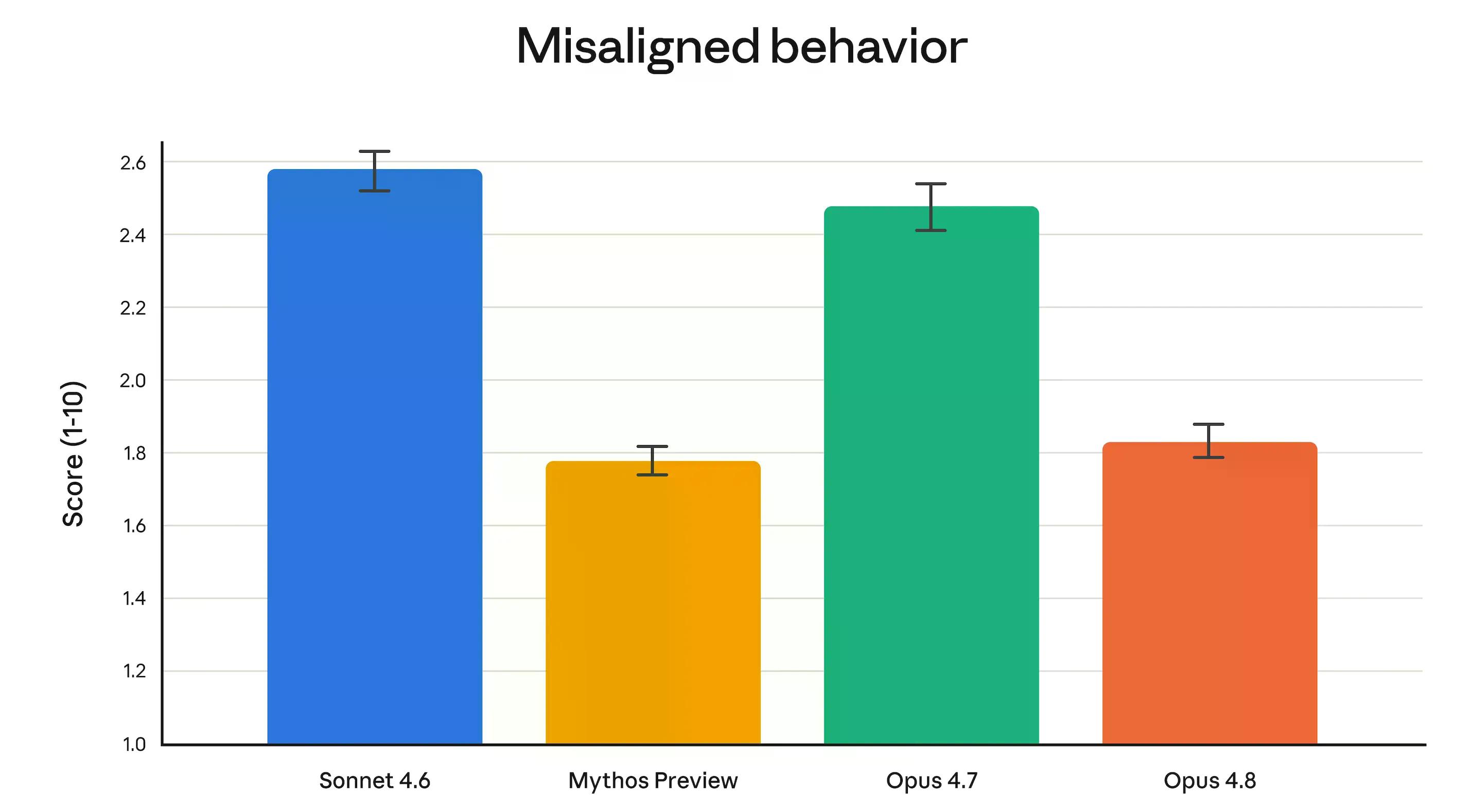
Anthropic 的對齊團隊表示,Opus 4.8「在支持用戶自主性並以用戶最佳利益行事等親社會特徵的衡量方面達到了新高」。更具體地說:欺騙率和濫用合作率顯著低於 Opus 4.7,並與 Anthropic 最受限制的模型 Claude Mythos Preview 相媲美。
Opus 4.8 讓自身程式碼中的錯誤悄悄通過而未被標記的可能性,也比 4.7 版本降低了四倍。
Mythos 的比較值得深思。Mythos 在層級上完全高於 Opus——Anthropic 將其描述為「比我們的 Opus 模型更大、更智能」。它目前僅以預覽版形式存在,透過 Project Glasswing 僅供少數經過審核的網路安全組織使用。
英國 AI 安全研究所發現,它能自主完成「最終之物」(The Last Ones)——一個需要人類紅隊耗費 20 小時才能完成的 32 步企業網路攻擊模擬。這就是為什麼它尚未上市。Anthropic 表示,更強大的網路安全防護措施正在開發中,並預計在「未來幾週內」將 Mythos 級模型帶給所有人。
今天也同步發布了:Claude Code 中的動態工作流程,目前處於研究預覽階段。此功能讓 Claude 能夠編寫自己的編排腳本,並在單次會話中啟動並行子代理、驗證其輸出並回報結果——就像 Hermes 長期以來一直在做的那樣。
動態工作流程適用於企業版、團隊版和 Max 方案用戶,Anthropic 公開表示,它們比標準的 Claude Code 會話消耗更多的 token。
Anthropic 每百萬 token 5 美元/25 美元的定價,與中國近期所做的相比,顯得大相逕庭。
DeepSeek V4 Pro 上週將其 75% 的折扣永久化:輸入 token 每百萬 0.435 美元,輸出 token 每百萬 0.87 美元。小米 MiMo V2.5 Pro 透過 OpenRouter 等供應商也以相同的費率運行。
Anthropic 的快速模式輸入每百萬 token 10 美元,輸出每百萬 token 50 美元——比標準的 Opus 4.8 本身更貴,而且輸出 token 的價格約是 DeepSeek V4 Pro 的 57 倍。企業已經在美國模型上的推理費用花費了數百萬美元。隨意使用 Opus,您的企業可能很快就會達到數百萬美元的花費。
Anthropic 對於價格差距的回應是品質和安全性。在 SWE-bench Pro 上,Opus 4.8 擊敗了兩款中國模型。在對齊方面,兩款中國模型都無法與 Anthropic 公布的基準相提並論。
這些因素在生產環境中至關重要,因為模型悄悄配合惡意輸入是一種實際風險——在受監管行業、法律工作以及任何「看起來沒問題」不是可接受的事故後報告的情況下。對於其他人來說,這個差距難以忽視。
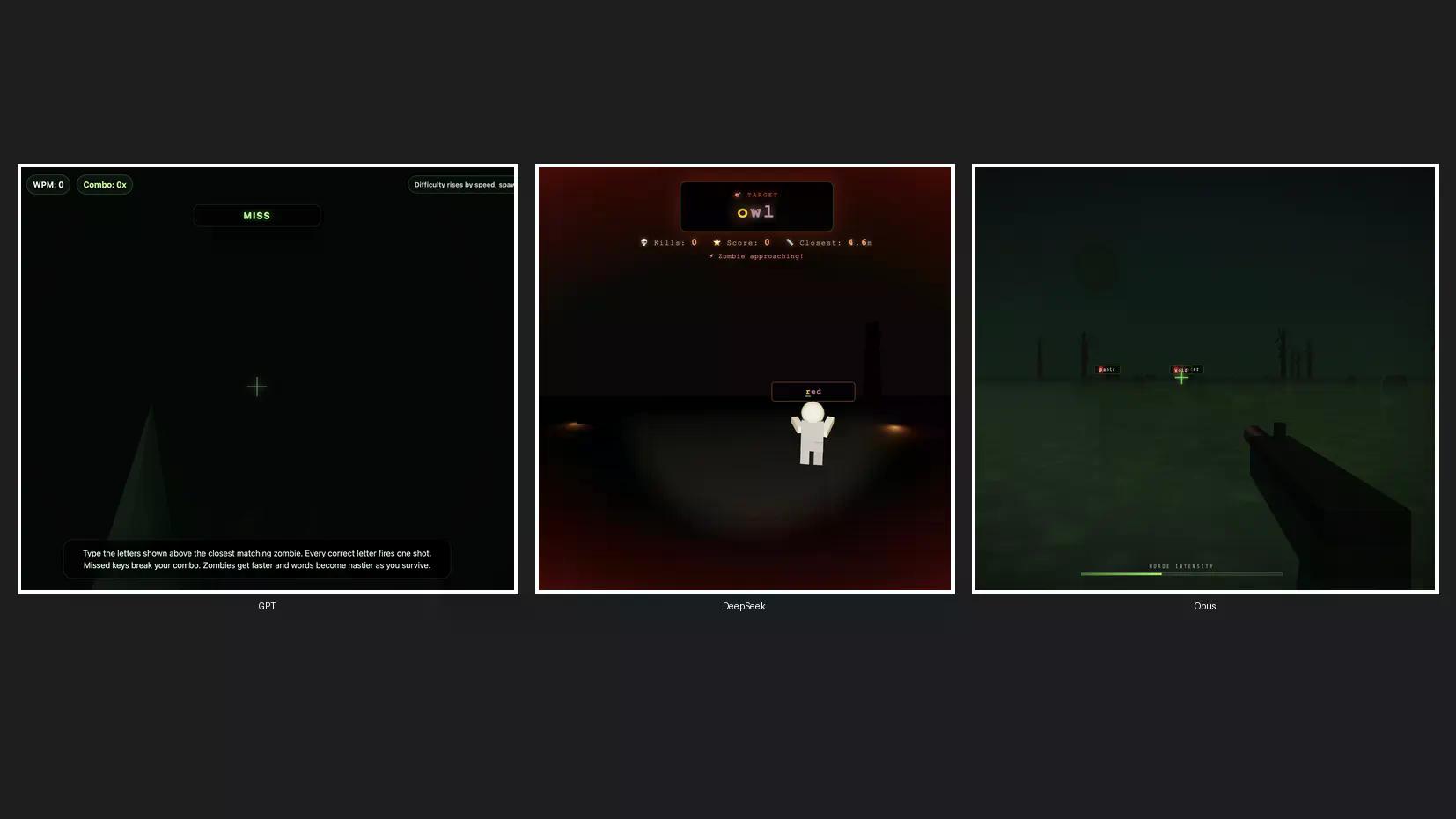
我們進行了一個快速的編碼測試,來創建一個 3D 殭屍遊戲,以觀察 Claude Opus 4.8 與 ChatGPT 和 DeepSeek 這兩個美國和中國最受歡迎的競爭對手相比表現如何。我們將 Opus 4.8 設定為預設高階,GPT-5.5 設定為高努力程度,DeepSeek V4 Pro 也設定為高努力程度——三個模型,一個提示,沒有重試。
GPT-5.5 最先完成。它的遊戲沒有殭屍視覺效果,也沒有音效。它確實很快,但完全未能達到要求。
DeepSeek V4 Pro 排名第二,它具備滑鼠移動、實際的殭屍角色、音效、紮實的遊戲機制和簡潔的美學。這方面沒有任何抱怨。
Opus 4.8 花費的時間大約是 GPT-5.5 的三倍,但提供了最好的啟動畫面、最佳的殭屍設計、最佳的遊戲機制和不錯的音效。它是最慢的,但卻是最佳的輸出。儘管如此,考慮到價格差距,這可能不足以證明它比 DeepSeek 更有使用價值。
所有遊戲都可以在我們的 Itch.io 個人檔案中找到。GPT-5.5 生成了「殭屍打字」(Zombie Typing),Opus 生成了「打字亡者」(Typing Dead),DeepSeek v4 Pro 生成了一個沒有名字的遊戲,直接讓您進入行動。我們稱它為「打字尋找」(TypeSeek)。
完整的比較評論即將推出。目前來看:對於這類任務,Claude Opus 4.8 的編碼能力優於 GPT-5.5 和 Opus 4.7,且價格與 Anthropic 自 4.7 版以來收取的費用相同。對於那些已經支付每百萬 token 5 美元的開發者來說,他們剛剛免費獲得了一個更好的模型。
